
Case Study
1 Introduction
Fána is an open-source feature flag management platform that facilitates testing in production. Software developers can release new features to targeted subsets of their user base, starting with their most bug-tolerant users like beta testers. By providing developers the means to toggle new features “on” for progressively larger audiences, Fána offers a tool with which to control testing in production safely and responsibly.
This case study will cover the tradeoffs of testing new features in production, how Fána enables it, and the engineering decisions the Fána team made during the implementation process.
2 Testing
When introducing new features to end users, developers need a process that is optimized for the speed and reliability of the release. Modern development teams often integrate automated testing approaches into their deployment pipelines (such as Continuous Integration and Continuous Delivery pipelines) to create rapid, iterative workflows in which frequent code changes can be deployed faster. Automated testing suites can include tests that range from specific in scope, such as unit testing for single functions and components, to more broadly scoped tests that test interactions between the components of the system and prevent regression from newly merged code (e.g.integration tests and end-to-end-tests).
Testing helps verify that an application as a whole behaves as intended and that the smaller components within the application communicate and integrate as expected[2]. In short, testing is the foundation required to "move fast with confidence"[3]
2.1 Testing Before Production
While automated testing can prevent code regression, it does not always represent how real users may interact with a system or fully portray the environment in which the system will run. Staging environments attempt to replicate production with as high fidelity as possible to facilitate more robust and precise insight into the quality and behavior of the system at large.

While the staging environment aims to replicate the production environment for pre-production testing, many outside factors can influence the performance and quality of a system running in production that is difficult or cost-prohibitive to replicate. Examples include:
- Race conditions
- Unpredictable user behavior
- Disparate runtime environments
- Unreliable networks, including external service dependencies
- Unpredictable user behavior

Even with robust automated testing suites and sophisticated staging environments, the production environment still represents unpredictable and irreplicable conditions.
2.2 Testing in Production Responsibly
If the combination of external factors and user behavior in production environments are unique and difficult to replicate in controlled staging environments, developers will ultimately need to gain confidence in the reliability of their release in ways that pre-production environments cannot offer. A better way to ensure a system’s expected performance under real user strain and in real network conditions is to evaluate that system in a real production environment. Deliberately testing in production, then, is a powerful tool by which developers can boost an application’s resilience to survive errors and bugs.
However, testing in production invariably poses some risk. Any change to a system can unexpectedly disrupt that system. Deployment failures can degrade the user experience, damage the reputation of both the product and the company, expose the company to regulatory scrutiny, or negatively impact the bottom line[4].
Developers who test in production can leverage different tools to limit the negative outcomes in event that a new release doesn’t behave as intended. One pattern to help mitigate these risks is to roll out changes to users gradually: releasing new code to incrementally larger portions of the user base. This approach helps limit the blast radius, the reach that any problematic changes might cause, by increasingly exposing those changes only as confidence permits.

A further evolution of that approach is structuring the stages of that incremental release pattern to target specific types of users or audiences. For example, a new feature can be enabled solely for developers initially, then for a beta testing user group, then early adopters, etc., and finally to the general audience of all users. Exposing unproven portions of the application only to more bug-tolerant subsets of the user base first offers a safe way to mitigate the negative outcomes of a problematic release.

As an example of this, when cloud computing company VMware started to outgrow an important conversation view feature in their app, engineers decided it was time for a total rewrite. While implementing the changes, VMware needed both to evaluate user feedback and investigate any issues experienced by real users, while also limiting its impact to the general audience of production users.

To meet their requirements, VMware chose to release improvements of their feature rewrite to only a small group of targeted users at first. The release would be open to the general audience only after iterating with those selected users. The process was executed within the context of a continuous release cadence by way of selective testing in production[5].
3 Possible Solutions
There are a few ways to target specific subsets of users with experimental features. For smaller teams looking to execute similar deployment approaches to that of VMware’s feature rewrite, two common approaches worth considering are Multiple Deployments and Feature Flags.
3.1 Multiple Deployments
A multiple deployments strategy consists of cloning the production environment and implementing the new feature as a separate production version. A load balancer then takes care of routing the desired users between both the original and new environments.

This comes with the benefit of cleaner application code - since routing logic is abstracted to the load balancer, each environment is solely responsible for serving one version of the application. This ensures that the newer version of the application won’t contain code references to older versions, which reduces the potential for technical debt.
Multiple deployment strategies like canary deployments also have the benefit of zero downtime for users: if something goes wrong with the new app, developers can route all traffic to the stable version. Also, since the routing logic can be configured in the load balancer, users can be selectively routed to specific experiences.
There are some trade-offs to consider with multiple deployments. For example, if three new features are included in a deployment but one of the features is not performing as expected, the entire application, including the two satisfactory features, would need to be rolled back.
Additionally, deploying multiple production environments requires additional cloud or infrastructure resources since there is more than one production environment online. This adds cost and complexity to monitoring and maintaining the additional infrastructure. As the need for more versions of deployments grows, more environments would need to be added to test different variants of the application which would compound the cost, complexity, and overhead to manage the various deployments.
The next section will explore using feature flags as an alternative approach to releasing a new feature.
3.2 Feature Flags
A feature flag strategy, at the lowest level, consists of conditional statements that determine whether or not a given block of code should be executed. In more practical terms, a feature flag is a means by which to gate the execution of that code based on the context or environment in which it is evaluated. In the below example, if the evaluateFlag function for the new_feature evaluates to true, the user receives the new feature; otherwise, they receive the old feature.

Because feature flags rely on conditional flow in the source code itself, feature flags are usually configurable remotely, meaning that the codebase can be untouched while the routing or evaluation logic changes.
As with multiple deployments, feature flags come with the benefits of zero downtime thanks to the ability to remotely toggle functionality. Additionally, since each new feature is tied to a single flag, this provides the advantage of selective rollbacks. If one out of three features is buggy, the developer can simply toggle that one feature off, while the others stay on.
Since the conditional logic lives in the code, this adds maintenance complexity to the codebase. This feature flag lifecycle requires increased coordination between teams, including the status of active and inactive flags, when old flags can be removed, and who has ownership over the governance of different flags. If not carefully managed, feature flags can contribute to significant technical debt, so proper governance is a significant consideration.
In addition to governance, there’s also the cost of additional loading time due to the network communication required to evaluate flags, since they’re managed remotely.
3.3 Comparing Multiple Deployments and Feature Flags
To revisit the key criteria for testing in production responsibly, the solution for a team looking to deploy a new feature with confidence needs to both facilitate strategic user group targeting and allow quick rollback of a problematic release with minimal downtime.
Further, to execute this approach as a smaller team looking to maintain high-velocity code deployment cycles, there are additional flexibility requirements:
- Resolving an issue with one feature shouldn’t disrupt the deployment cycle of other changes. If possible, handling problematic features should have minimal collateral consequences for the deployment at large.
- Deployments and releases should be decoupled. By decoupling feature changes deployed to production from feature changes exposed to users, developer teams can reconcile long-term development with rapid iteration, as with VMware’s feature rewrite.
While feature flags introduce additional complexity to a codebase, they present some distinct advantages as a deployment tool. While both a multiple deployments strategy and feature flagging strategy can accommodate targeted release audiences and expedient rollbacks, a unique benefit of a feature flag platform is the flexibility to isolate individual features to enable or disable them as needed.
4 Feature Flags for Testing in Production
Feature flagging provides the ability to selectively enable and disable features in real-time, as well as the ability to designate specific audiences. This makes it a suitable tool for developers who wish to test their features in production.
There are various ways to use feature flags, including standard toggling, percentages, unique identifiers, and attribute/audience targeting.
4.1 Standard Toggling
Feature flags offer the ability to remotely toggle functionality entirely on or off. This means that the developer can use a flag to release a new feature, and if something goes wrong, it can simply be toggled off.

However, this new feature would be released to the entire user base. Despite the speed of remotely toggling the feature off, wholesale release to the entire user base may still not be the best option because all users are potentially impacted by any problems. A standard toggle functionality isn’t quite enough - there needs to be a way to narrow down the number of impacted users.
4.2 Percentage Rollout
One way to limit the impact is to adopt a percentage rollout strategy. This means users will be randomly sorted into the available experiences based on a predetermined rate. For example, the developer can have the new feature only serve 10% of their user base, limiting the potential impact of a negative experience.

While this helps, percentage rollout does not provide granular control over which users will receive certain experiences. This may be more suited for a use case like A/B testing where the developer wants to be indiscriminate about who sees the experimental feature. A more responsible approach to testing in production would be to specifically target bug-tolerant users.
4.3 Unique Identifier
One way to target bug-tolerant users is to designate a flag rule to target users based on a list of unique identifiers. This identifier can be anything that the developer has access to, like an user ID or IP address.

This may allow developers to target specific, bug-tolerant users at an extremely granular level, but it can become cumbersome as the target user list increases. This can bloat the flag ruleset and make it difficult to manage when targets need to be removed.
4.4 Attributes
Feature flags can also be evaluated based on developer-defined attributes. These attributes can be general user information, session context, environment values, etc, used to conditionally execute application logic. Attributes facilitate a more flexible and granular approach by providing a means for deliberate criteria-based targeting according to whatever evaluation context values a developer chooses.

As a simple example, a developer may be trying to target west coast students for an experimental new feature. Their flag would target anyone that has their student attribute as true and their state attribute as either California, Washington, or Oregon.
To take it a step further, developers can bundle multiple attribute-based rules into groups, also known as audiences. Audiences are a set of rules based on those developer-defined attributes, and they offer convenient reuse of targeting criteria composed of more complexly structured or numerous attribute qualifications. This can be particularly useful when testing in production, as a single audience can be used for any flags without needing to redeclare any of the conditional attribute logic.

If the example feature flag is modified to target West Coast Students, a developer can bundle the student and state attribute together to create this audience. Now, instead of having to set student to true, and state is California, state is Washington, or state is Oregon on every flag, developers can simply declare those requirements on the West Coast Students audience, and reuse the audience in the relevant flags.
To revisit the case of VMware as a practical example, the engineering team utilized feature flags wherever the old feature was referenced in the existing code base, allowing different versions to be served to different users.
To implement this, VMware created three separate user audiences: Developers, Beta users, and General Audience. Different versions of the feature were served by evaluating the respective feature flags based on which audience the user was in. This allowed the engineering team to test new iterations of the feature in production as they were being developed.

Once a feature completed the requisite internal testing, it was made available to Beta target users. This allowed VMware to collect user feedback and update the feature accordingly. Because of the size and scope of the feature, VMware iterated through several testing cycles within the Beta users before moving forward to the General Audience stage in production. Still, even once the feature was generally available, it could be easily disabled via toggling off the associated feature flag. This would effectively revert to the pre-rewrite version of the feature while issues with the new version could be investigated and resolved.
5 Implementation Options
There are several options for teams looking to release features to targeted audiences using a feature flagging solution: DIY in-house implementations, commercial options, and open source options. Each of these options has distinct strengths and limitations.
5.1 DIY
One option to implement a feature flag platform is to build an in-house solution. To build one that accommodates audience-targeted releases, a DIY solution would need the following core features:
- flags need to be evaluated dynamically and in real-time to execute rapid rollback of problematic features; and
- a consistent data source to hold flag definitions and audience rules (i.e., which users see which features).
Architecturally, the above requirements necessitate several components to implement a minimum viable feature flagging platform:
- a persistent backend data store for flag data, audience rules, and the targeted attributes that compose those rules;
- a developer interface, like on a command line, by which to manage that data set: toggle flags, adjust the composition of audiences, etc; and
- a package embedded in the application to execute the appropriate flagged features within the application.

Going the DIY route is a viable option, however, building a bootstrapped feature flagging system poses many challenges. For example, Atlassian built its own system primarily to control feature releases. As more teams wanted to use the in-house solution, developing and maintaining the solution became unwieldy. In addition, the system was not designed for users outside the development team. Without a user interface, teams outside of engineering, such as Product Management, had to rely on the engineering teams to manage flags and run beta tests[6].
While building an in-house feature flagging platform provides deployment flexibility and data privacy, there’s a significant cost in the engineering team’s available resources to build the tool out initially. It’s also likely that continuous work may be required to maintain and evolve the platform moving forward.
5.2 Open Source
Leveraging open-source solutions is a cost-effective way to build a customizable feature flagging platform while maintaining data ownership through self-hosting. However, there are a few notable tradeoffs of using open-source solutions:
- Fewer features out of the box than paid solutions (e.g. experimentation, A/B testing, workflow integrations)
- Dedicated resources are needed to build and maintain the feature flag platform
For example, FeatureHub offers the ability to implement targeting rules based on attributes but can't group those rules into audiences. The lack of reusability results in a tedious process of manually setting up rules on each flag. Unleash does have audience targeting (they call them segments), but only as part of their paid tier plan. Therefore, building off these open source solutions still requires additional resources to implement flexible and reusable audience targeting functionality.
5.3 Paid Solutions
If the resource overhead or lead time of implementing a DIY solution is too prohibitive, there are several robust feature flag solutions on the market offering paid options. These save time and resources by providing rich and convenient functionality out of the box. There are a few options here, but two of the most popular ones on the market are LaunchDarkly and Optimizely.
Premium solutions come with a lot of built-in support for experimentation, workflow integrations, and segment targeting. However, with these benefits come some considerations:
- Paid: These enterprise solutions generally come at a monthly cost per user, which may be prohibitive to smaller companies.
- Not self-hosted: Flag data and targeting rules may contain sensitive information, which can be problematic in cases where there are legal restrictions on sharing data with a third-party service.
5.4 Weighing the Options
A developer team looking for a high degree of flexibility and customization can opt for open source solutions to bootstrap a DIY feature flag implementation or build an in-house solution completely from the ground up. While flexible and customizable, the DIY route may carry a higher cost in the way of engineering resources and time.
For broad and proven functionality out of the box, a developer team can consider enterprise solutions like LaunchDarkly. However, some tradeoffs with using third-party services include:
- Cost: Certain features like targeting specific audiences are accessible through a monthly fee.
- Data privacy: Potentially exposing user data or company data to a third-party database.
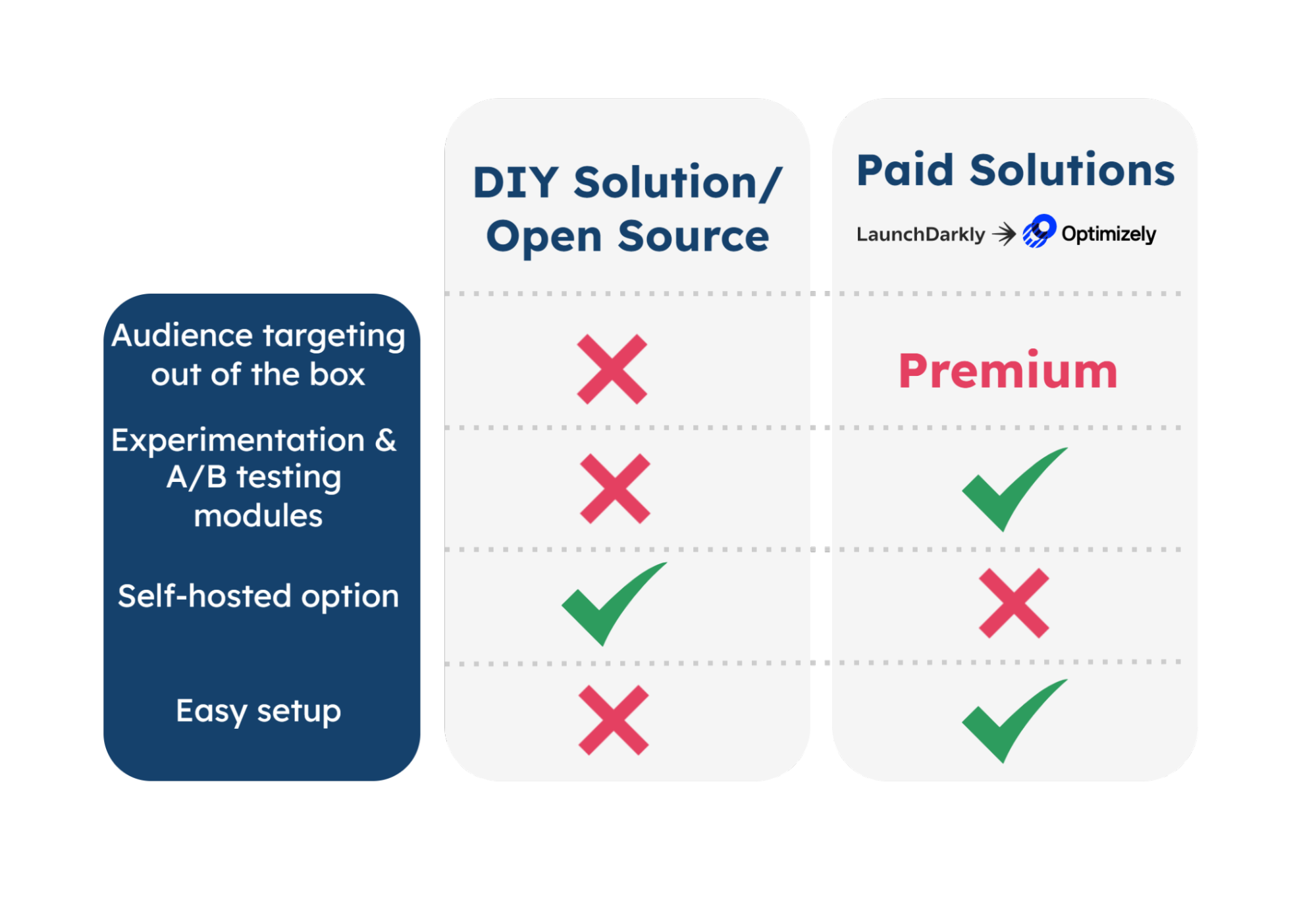
For a smaller, budget-conscious developer team that needs audience targeting functionality for testing in production out of the box and prioritizes data privacy, an enterprise solution may not meet their needs.
The next section introduces a Fána, an alternative feature flagging solution.
6 Fána
Fána occupies a niche in between, offering the ready-made functionality of a third-party solution for development teams specifically looking to utilize feature flagging to target audiences.
Fána offers a simple, straightforward frontend interface to manage flags and their audiences, making for an intuitive user experience with a minimal learning curve. Additionally, while Fána can be self-hosted to maximize data hosting flexibility, the option of automated deployment to Amazon Web Services (AWS) offers the most convenient solution to get up and running more quickly.

Fána allows developers to selectively serve experiences to particular audiences while allowing for remote toggling in real-time. This is particularly useful when testing in production, as developers may wish to only serve a new feature to bug-tolerant groups. If something goes wrong, developers can flip the switch to turn that feature off instantly.
To implement audience targeting via feature flags, Fána makes use of a set of entities to describe, assess, and target users as discussed in the following sections.
6.1 Fána's Entities
Fána has three closely related entities at its core: Attributes, Audiences, and Flags. Together, they enable Fána users to target intentional segments of users within their application.
6.1.1 Attributes
The first entity that a Fána user would need to consider is attributes. Attributes are qualities that serve to describe a user. The values assigned to these attributes–which can be of data types strings, numbers, or booleans–are used to evaluate a user’s eligibility against the conditions within an audience.
After creating an attribute, Fána users can include it when creating and configuring their audiences.
Creating an Attribute in the Fána Dashboard
Below is an example of the Fána dashboard creating three new attributes, one of each data type.
User Context
A user context is an object composed of attributes-value pairs and is defined within the Fána user’s application code to provide relevant information about a user. Note that the user context is developer-defined, so it can consist of any data that the developer has access to. For example, a user context can have attributes describing the user’s location, age, and whether they are a student.

This user context is then used to assess whether the specific user satisfies the conditions to be part of the targeted audience.
6.1.2 Audiences and Conditions
Audiences are reusable collections of logical conditions. Conditions are made up of three parts:
- Attribute: the user qualities described above
- Target value: the value that is to be compared against the user context’s attribute value. In the previous attribute example, the
stateattribute is a string, so any string value can be designated as the target value:CAorWA. - Operator: how the attribute and target value will be compared against each other. The available options differ based on the attribute’s data type. String-typed attributes have various options, such as
is equal to,contains,starts with, and can even support multiple values with theis inoperator.
An example of a whole condition is “state is in CA, WA”. This means that any user context with a state attribute with its value as CA or WA would meet this condition.
Audiences can also configure their combination indicator, which is how the evaluation should be handled if there is more than one condition.
- If the combination is
any, it means that the user context only needs to meet one of the conditions to qualify for this audience. - If the combination is
all, it means that the user context must meet all conditions to qualify for this audience.
Creating an Audience in the Fána Dashboard
Below is an example of the Fána Dashboard creating a new audience called West Coast Students that has two conditions with an all combination. To qualify for this audience, the user context must meet all conditions: student attribute set to true, and state attribute set to one of CA, WA, or OR.
After creating an audience, the Fána user can target it when creating and configuring their flags.
6.1.3 Flags
Flags are the core entity of Fána. Each flag is meant to represent a specific feature that the Fána user wishes to test. They consist of four properties:
- a title, which helps the Fána user to easily distinguish between flags;
- a key, the identifier string that is used to evaluate a specific flag when using the Fána SDK within the developer’s app code;
- a toggle, which indicates whether this flag is enabled or disabled; and
- a list of targeted audiences for which the user context must qualify for any to evaluate
truefor this flag.
Creating a Flag in the Fána Dashboard
Below is an example of the Fána Dashboard creating a new flag to target the previously created West Coast Students audience.
Once a flag is created, the developer can use the flag key in their code when calling the evaluateFlag method, provided by the Fána SDK (more about SDKs in section 6.6).
The following sections will discuss the overall architecture, different components of Fána design in detail, and how these components communicate within an event-driven architecture to support real-time updates and audience targeting.
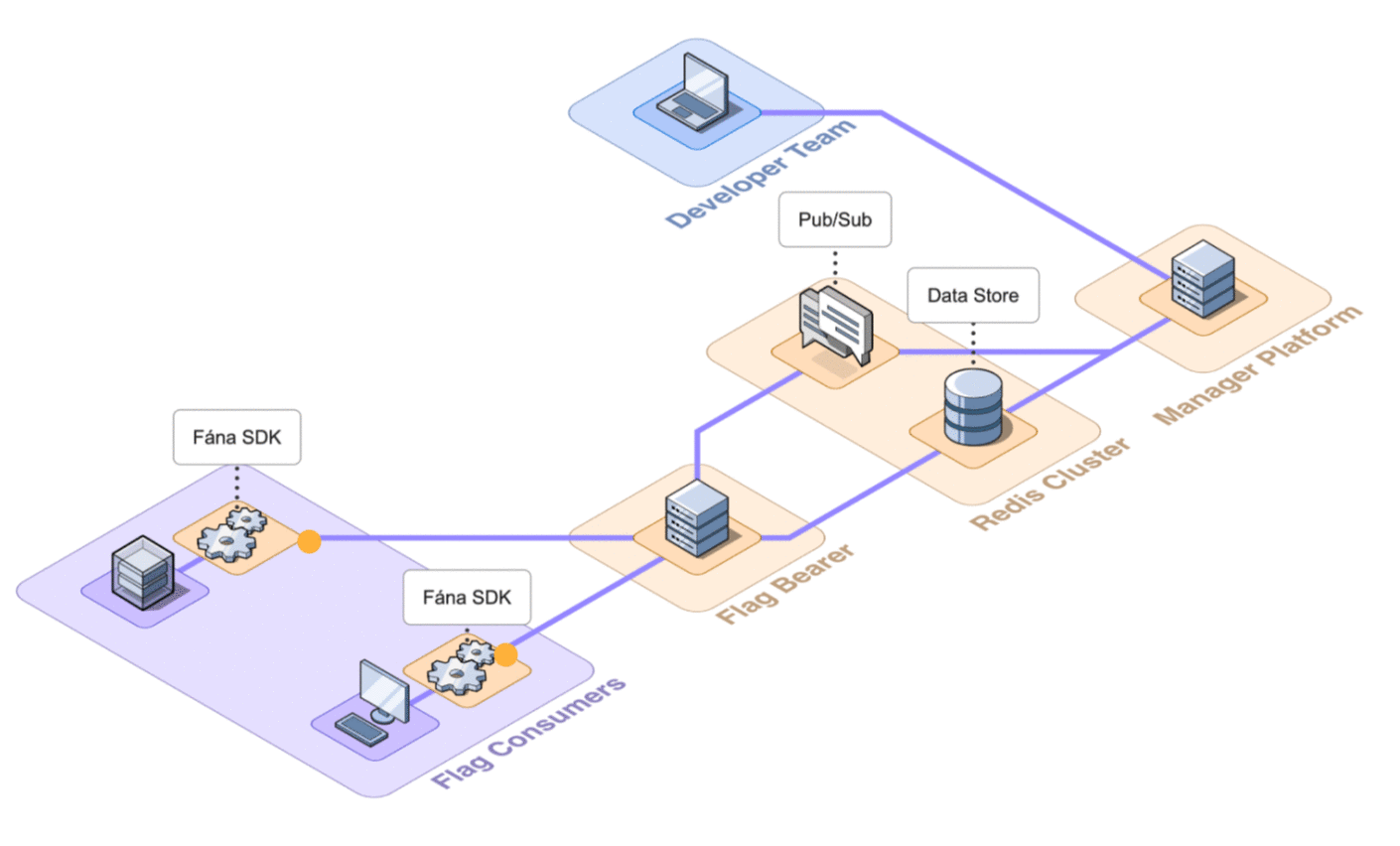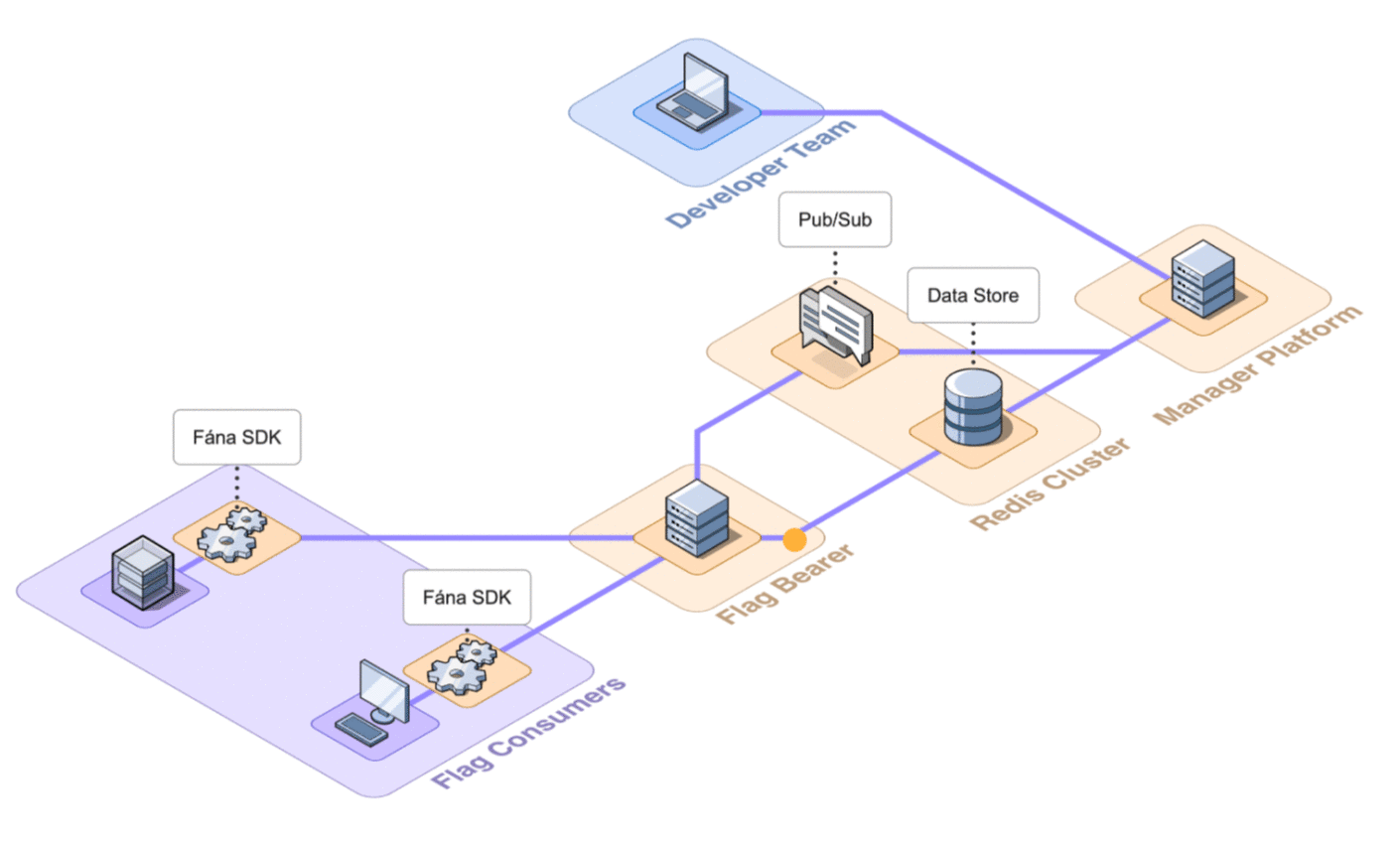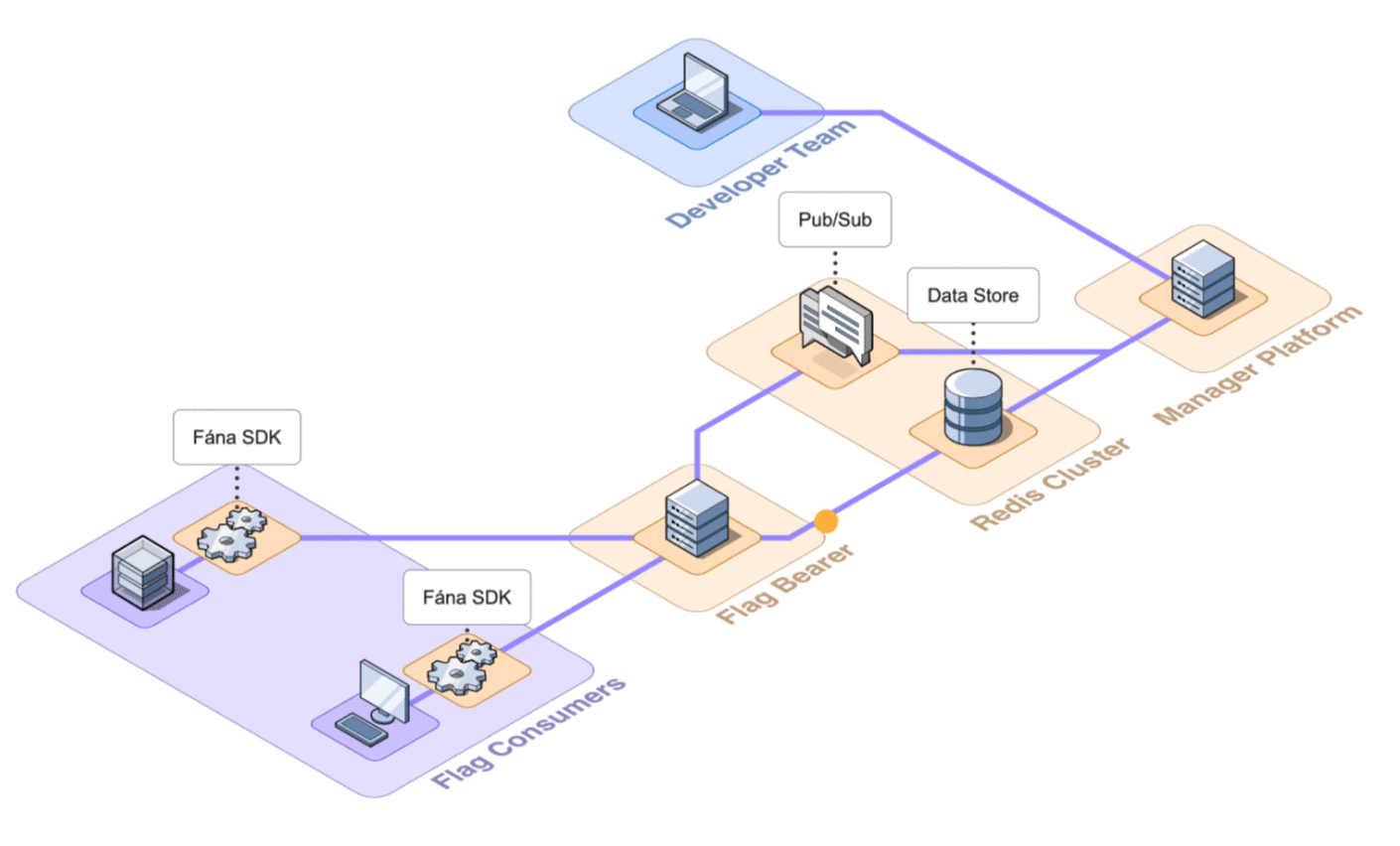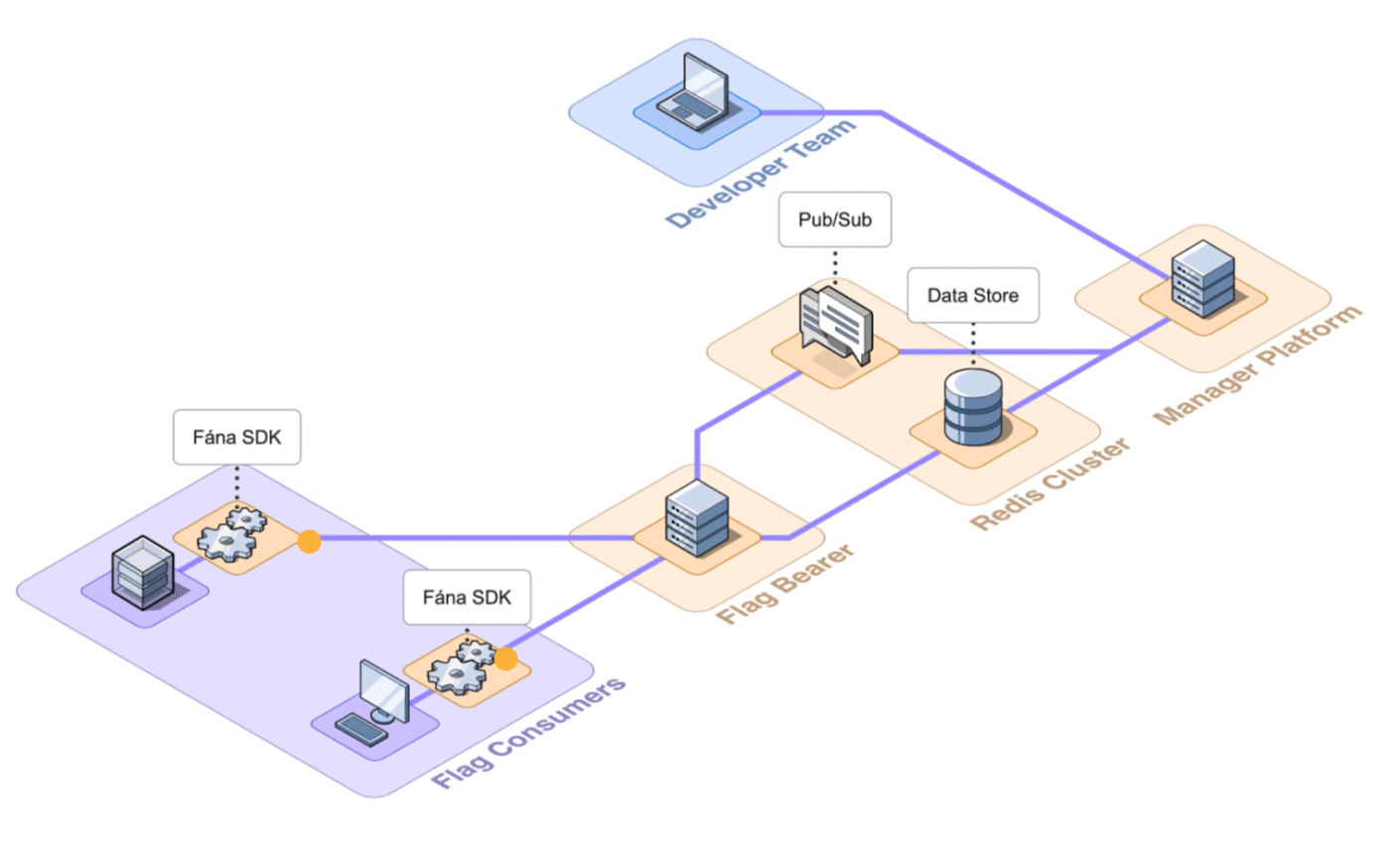
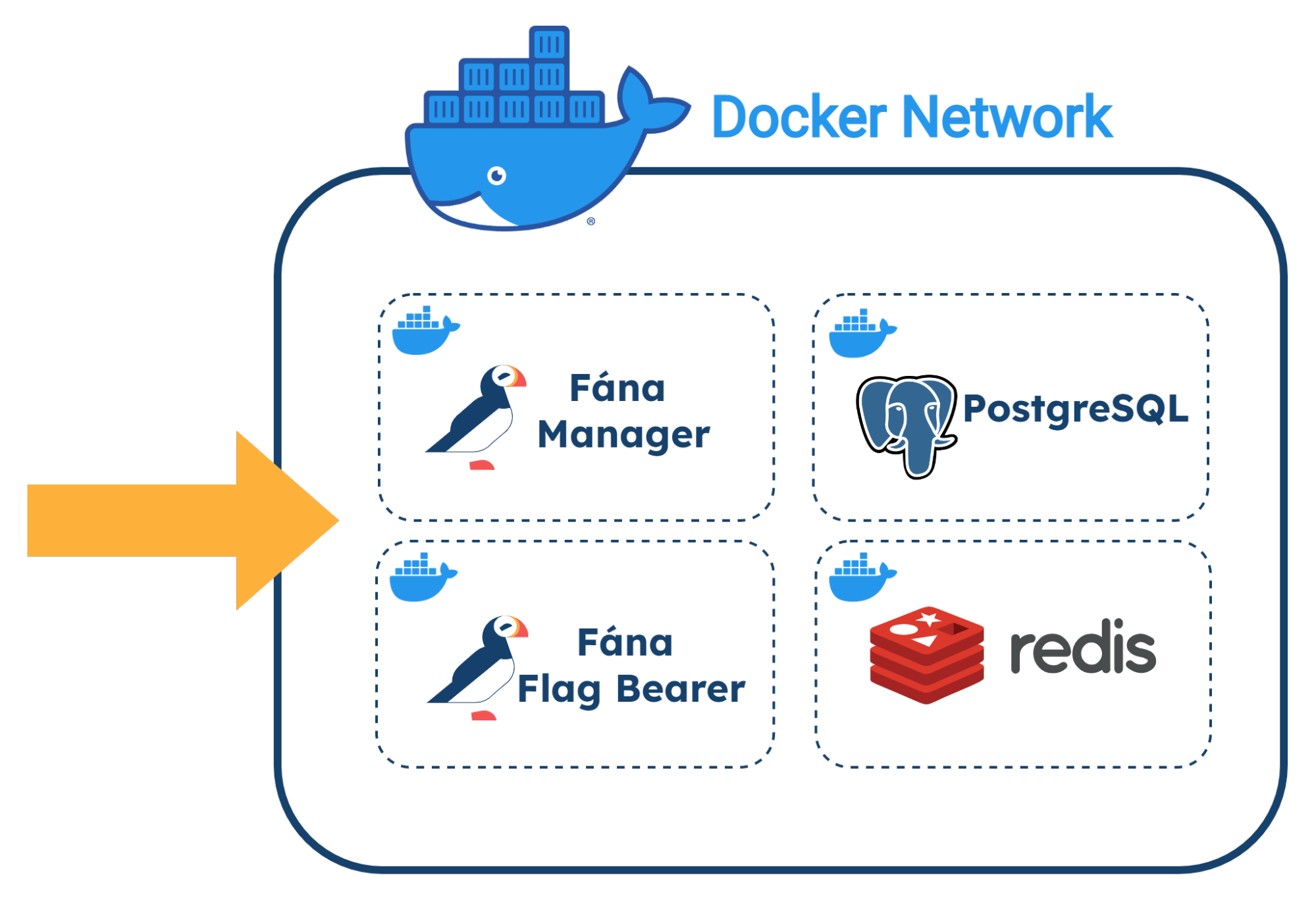
6.2 Architecture Overview
Fána’s architecture is divided into four major components: the Manager Platform, the Data store and Pub/Sub (Redis cluster), the Flag Bearer, and the Fána software development kits (SDKs). While the Manager Platform, Redis cluster, and the Flag Bearer can be containerized and hosted separately, the SDK component is embedded into the client’s application and configured to communicate with Fána’s Flag Bearer.
These components make up Fána’s event-driven architecture (EDA), where events--like changes or updates to flags--are used to trigger communication between the components.
There are three key pieces to any EDA:
- An event producer, which generates the events
- An event router, which directs the event notification to its destination
- An event consumer, which uses the event notification for some purpose
True to EDA philosophy, Fána’s components are designed so that each component is decoupled and can accommodate scaling.

A general overview of the major components and their responsibilities are as follows:
- The Manager Platform consists of the UI dashboard, which is used to manage flags and audiences. It also includes the Manager API which is in charge of handling data changes and serves the dashboard. This represents the Producer component of the EDA.
- The Flag Bearer manages SDK initializations, evaluates flag data for each user context, and forwards updates to the SDKs in real-time. This represents the Router component of the EDA.
- The Data store keeps a copy of the flag data from the Manager so that the Flag Bearer can use it for initializations. It also serves as the Pub/Sub service, where the Flag Bearer can subscribe to different channels for real-time updates.
- The client and server-side SDKs are embedded into the developer’s application and are responsible for enabling flag evaluation within the app. This represents the Consumer component of the EDA.
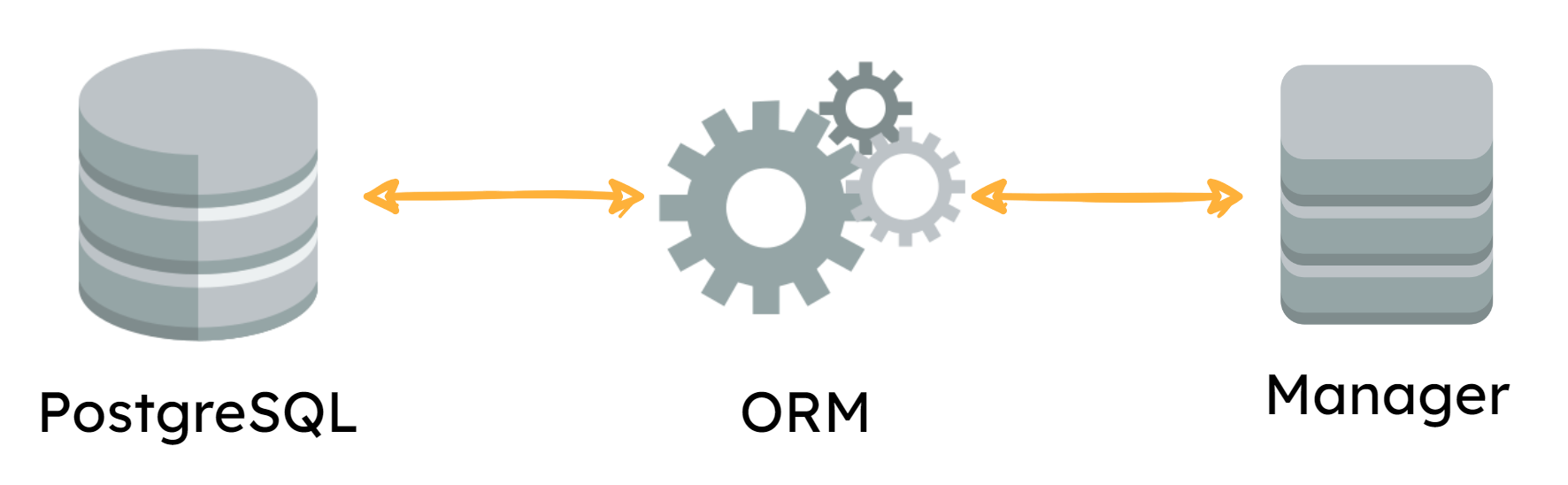
6.3 Manager Platform
The Manager Platform serves as the single source of truth for data related to flags and consists of a dashboard user interface and the backend API server that connects to a persistent PostgreSQL database.

The dashboard is the entry point for developers to the Fána feature flag platform. To utilize audience-based feature flags in their applications, developers need to first create a set of attributes, audiences, and flags through the Fána dashboard as discussed in Section 6.1.
The Manager is a Go application that serves the static files for that dashboard. It also fulfills several other responsibilities:
- Serving the RESTful API the dashboard consumes to manage flag data
- Executing all database operations by way of an ORM to reinforce the data model at the application layer
- Handling communication of flag data and updates to the SDK side of the architecture by publishing those messages both to the Pub/Sub and the Redis store
6.4 Flag Bearer
The Flag Bearer sits in between the SDK clients and the Manager Platform. The Flag Bearer is responsible for managing SDK connections and evaluating flag values.
Whenever an SDK tries to make an initial connection, the Flag Bearer is responsible for verifying that the SDK key in the request is valid. It then compiles the relevant data and sends it back to the SDK.
During the initialization process, the SDK will also request to open a persistent streaming connection. The Flag Bearer keeps track of these connections so it can forward the proper updates from the Manager to the SDKs that need them.
The Flag Bearer has multiple endpoints for the SDKs to connect to:
- Client-side initialization: The Flag Bearer uses the user context provided in the initialization request to pre-evaluate all flags, which are returned to the client-side SDK.
- Server-side initialization: The Flag Bearer returns the full flag ruleset to the server-side SDK. Server-side SDKs evaluate flags locally at runtime.
- Stream connection: The Flag Bearer subscribes the SDK to its respective stream (server or client-side), enabling real-time updates to flag data to be reflected in the SDKs using server-sent events (SSE).
6.4.1 Flag Evaluation
When the Flag Bearer receives an initialization request specifically from a client-side SDK, the Flag Bearer must pre-evaluate the flags for the provided user context (the reasons for this are described in section 6.6.2).
The Flag Bearer starts by fetching the full flag ruleset from the Redis data store. If the data store is empty or down, then the Flag Bearer will request the data from the Manager backend directly. The Bearer then processes the ruleset, along with the user context provided in the request to generate and respond with boolean evaluations of the flags back to the client-side SDK.
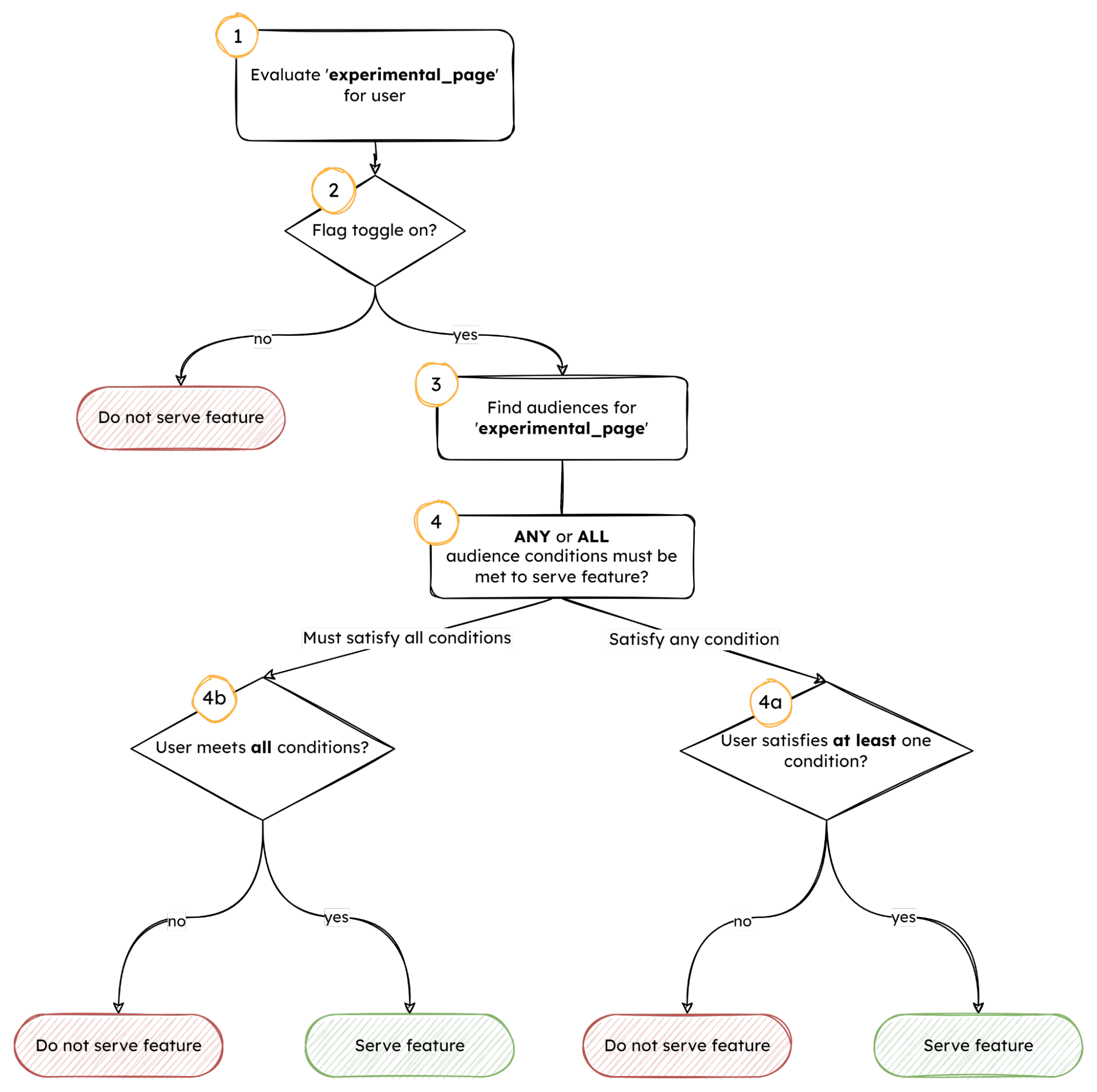
Here’s an example of how the evaluation logic works:
- A flag key,
experimental_page, is selected for evaluation. - This flag key contains information about its targeted audiences, including the conditions that a user must fulfill to be considered part of this audience.
- The
experimental_pageonly has one targeted audience for simplicity. - The flag toggle setting is assessed.
- If the flag is OFF, the
experimental_pagewill not be served. - If the flag is ON, the flag’s audience list is inspected to assess whether the user context meets the audience conditions.
- The targeted audience has a combination indicator that determines how each audience is evaluated.
- The
anycombination means that the user must fulfill at least one of the conditions to be eligible. - The
allcombination means that the user must fulfill all conditions to be eligible. - From there, each condition of the audience is evaluated. Depending on the combination indicator, the evaluation can be short-circuited so it doesn’t always need to process every condition.
- If the combination is
any,experimental_pagewill be served as soon as the condition evaluatestrue. If the user context never meets a condition,experimental_pagewill not be served. - If the combination is
all, if the user context meets all conditions,experimental_pagewill be served. However, as soon as the user context fails to meet a condition,experimental_pagewill not be served.
Note that flags can have more than one audience. In these cases, if a user is not eligible for an audience, the function will continue looking at the rest of the audiences until it finds one for which the user is eligible. The user only needs to be eligible for one audience to receive a final evaluation of true.
6.5 Redis Store and Publisher/Subscriber
The purpose of the Redis Cluster in Fána’s architecture is twofold: Fána uses Redis as a caching layer for flag data and as a message broker in a publisher/subscriber (pub/sub) model to push real-time updates to SDKs.
The Redis key-value data store holds the flag data for the Flag Bearer. The Manager backend is responsible for refreshing the data store with the latest flag data whenever an update is made to a flag or audience. Whenever a change is made, the backend writes to the database and the Redis data store. The data store is accessed by the Flag Bearer when any SDK initialization requests come in.
A common pattern to facilitate uni-directional communication in event-driven architectures like Fána’s is to utilize a message broker. Message brokers are useful intermediaries, particularly in scenarios where one component is sending messages to potentially many components in a distributed system[7]. Fána’s Redis cluster also serves as a message broker to facilitate the event-driven messages between the Manager backend API service and the Flag Bearer. The primary benefit of the pub/sub model is that it decouples communications between the Manager and Flag Bearer, where the Manager publishes messages to various channels to which the Flag Bearer subscribes. A key feature of a pub/sub model is that the publisher does not need to know about any of the subscribers or do anything different for a consumer to start receiving messages. This worked well for Fána, as the Flag Bearer layer can scale without the Manager needing to know about any new Flag Bearer nodes that come online. Each Bearer node automatically subscribes to the appropriate channels and can start receiving event-driven messages immediately.
Fána’s pub/sub implements two different message channels for flag updates: general flag updates and flag toggle updates. When any changes are made to the flag resources, the Manager backend will both write to the data store and publish a message with the updated data to the Pub/Sub, which is forwarded by the Flag Bearer to existing or open SSE connections with SDKs.
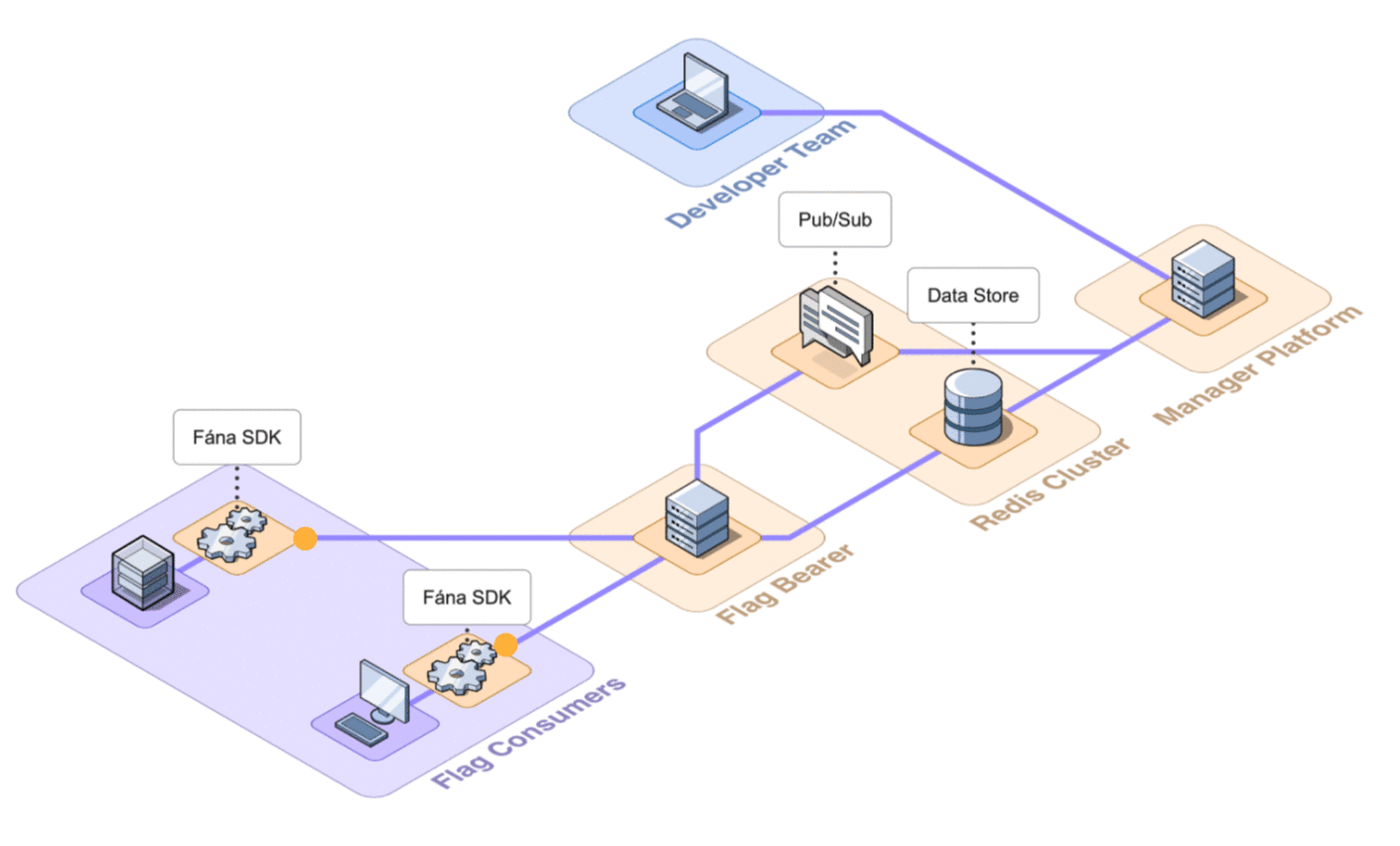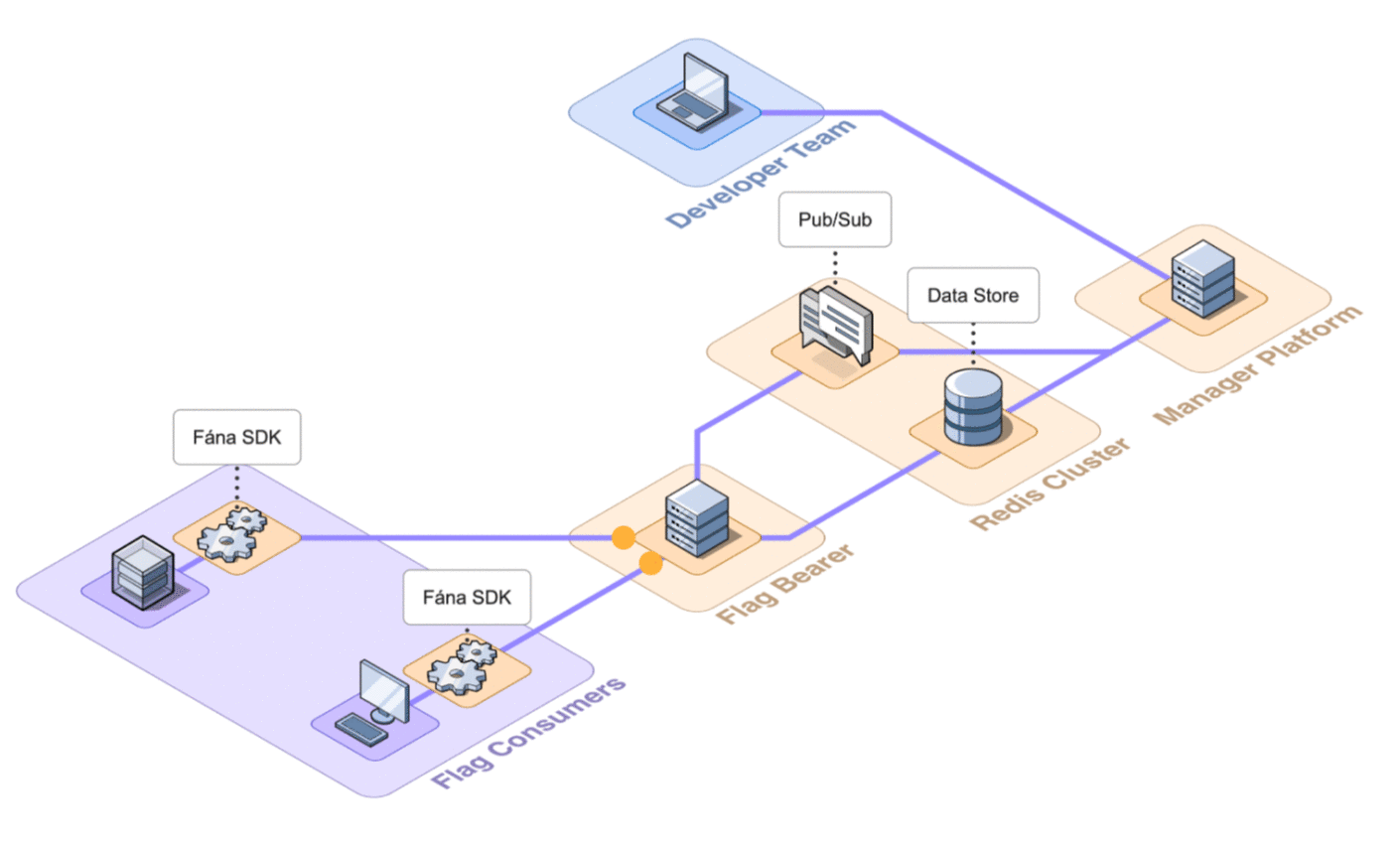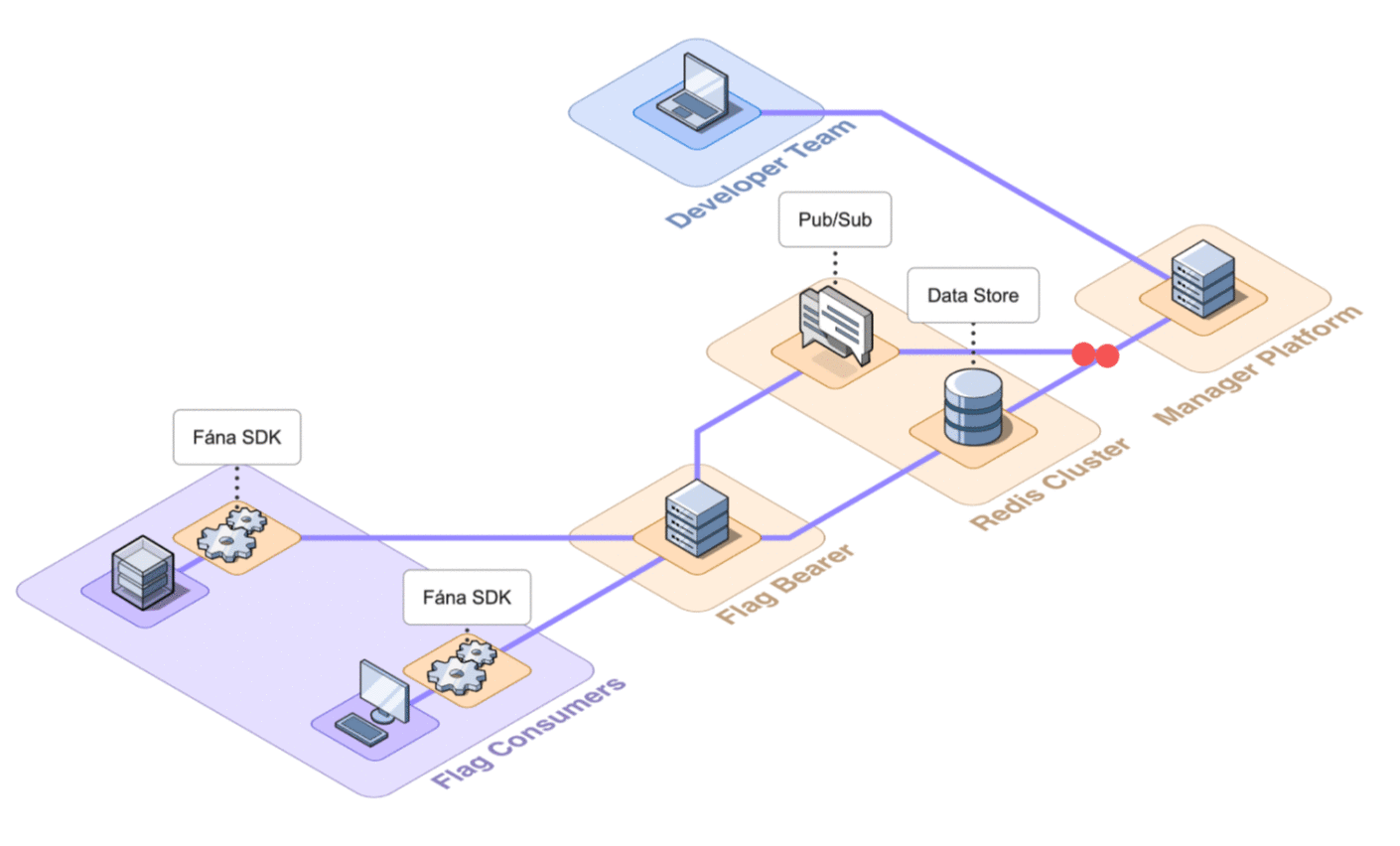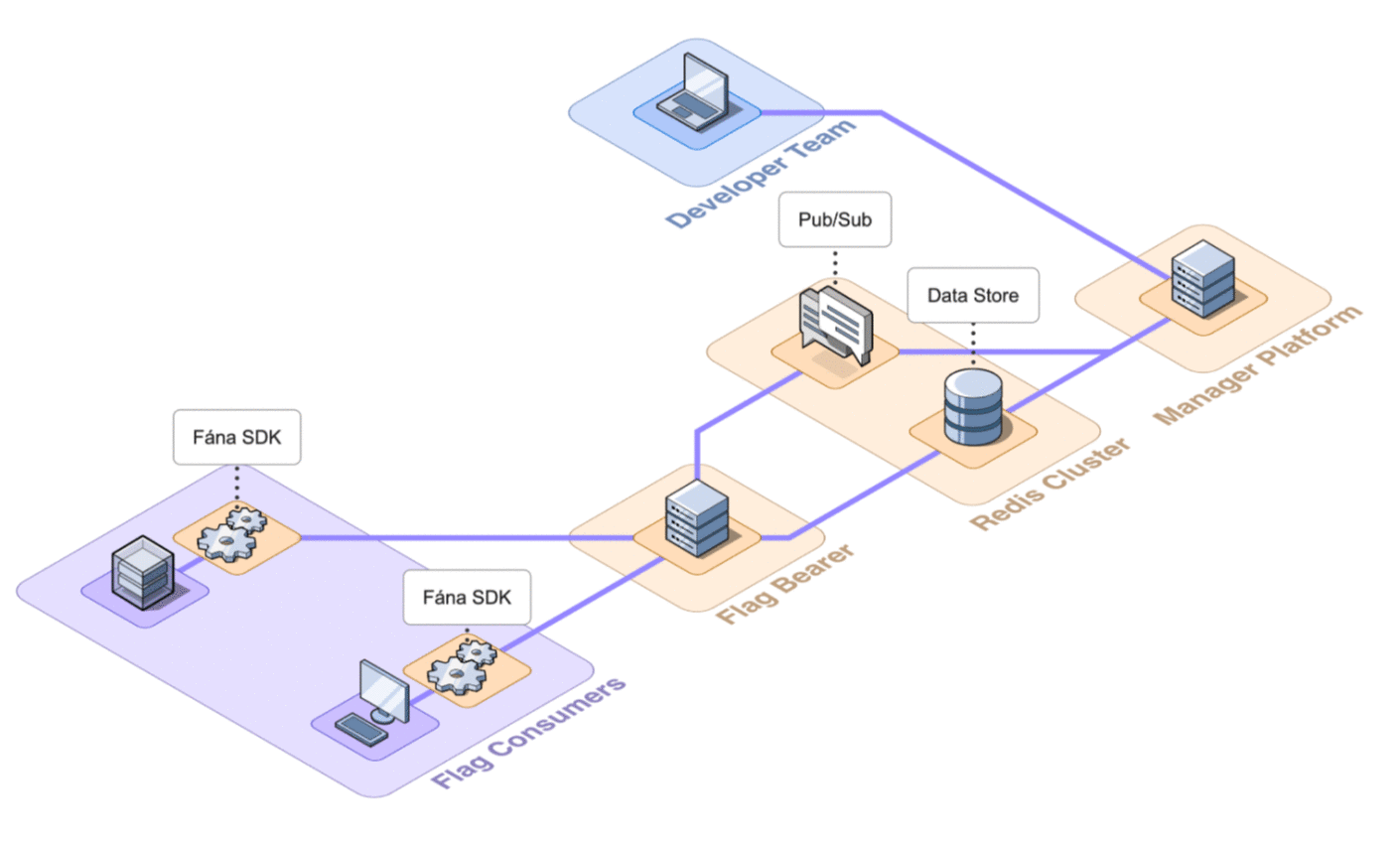
When an SDK sends a request to initialize an SSE connection with the Flag Bearer, the Bearer verifies the SDK key and subscribes the client to the appropriate Pub/Sub channel based on whether it is a client-side or server-side SDK. Once the SSE connection succeeds, the SDK can receive real-time updates whenever changes to a relevant flag happen.
6.6 Software Development Kits
Fána provides SDKs for React (client-side) and Node.js (server-side). The SDKs are responsible for instilling applications with the ability to evaluate flag keys. The initialization and flag processing is quite different between the client and server SDKs, so we will discuss each separately.

6.6.1 Server-Side SDK
To initialize a server-side SDK, the developer must provide two required arguments - the server-side SDK key and the address of the Flag Bearer. Then, whenever the server is run, the SDK takes care of reaching out to the Bearer with the provided information, which verifies the SDK key. Upon verification, the Bearer sends back the entire flag ruleset, which the SDK stores in memory, ready for evaluation.

During the initialization process, the SDK will also set up an SSE connection with the Flag Bearer using the EventSource API. This allows the SDK to receive real-time updates to flag data from the Flag Bearer.
Now, the developer is ready to use the evaluateFlag method. By passing in the flag key and user context, the SDK will determine whether this particular user qualifies for this flag based on the stored ruleset, and returns true or false. There is also the option to provide a default boolean value in case the provided flag key isn’t found, in cases of initialization failures. This evaluation process follows the same decision tree illustrated in section 6.4.1.
6.6.2 Client-Side SDK
Initializing the client-side SDK is different due to privacy concerns (elaborated on later in this section). In addition to the key and Bearer address, the developer must also pass in the user context object.
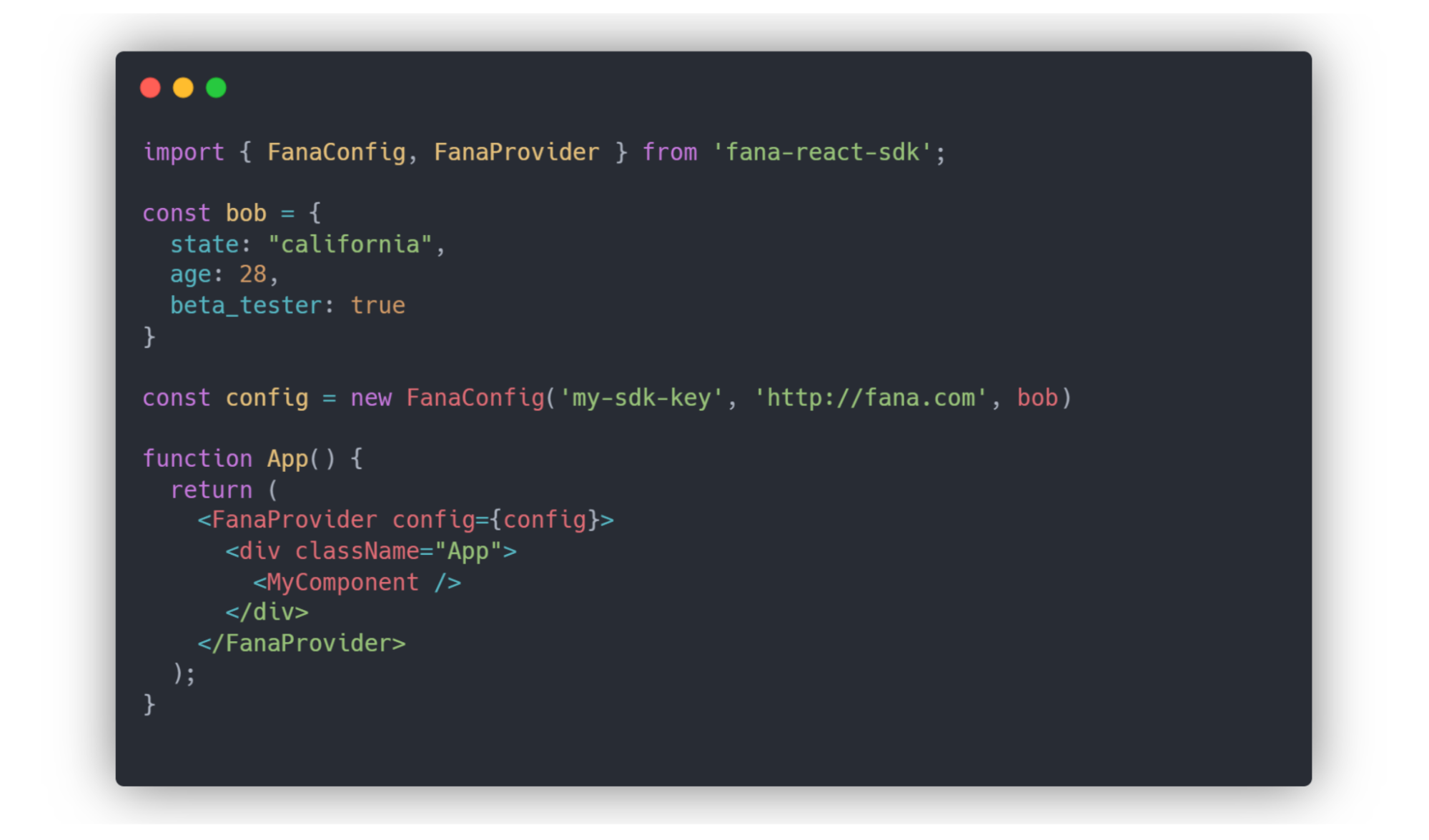
Whenever a client instance is spun up, the client SDK, similarly to the server SDK, reaches out to the Bearer with the provided information. After verifying the SDK key, the Bearer pre-evaluates all of the flag keys using the provided user context, and only sends back a hashmap of flag keys with true and false values. This hashmap is then stored in memory in the SDK.
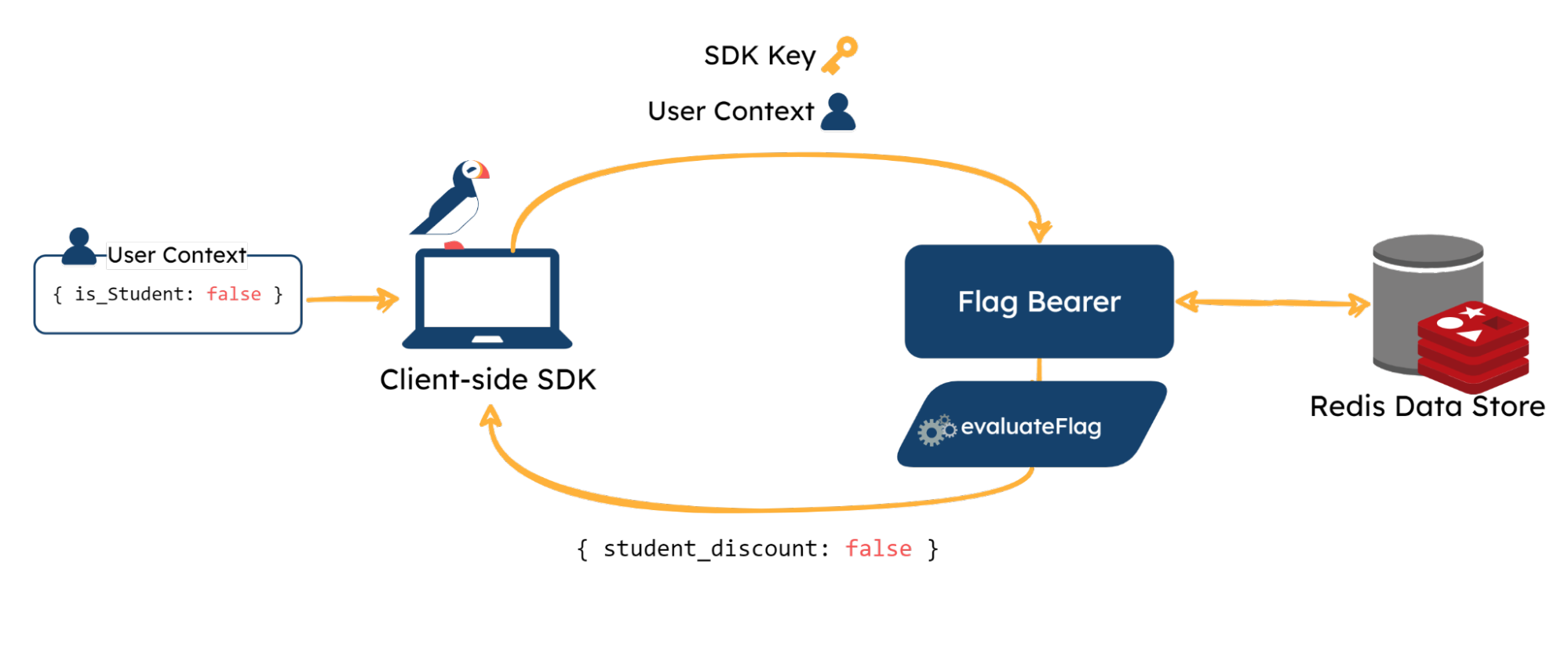
During the initialization process, the SDK will also set up an SSE connection with the Flag Bearer using the EventSource API. This allows the SDK to receive real-time toggle-offs from the Flag Bearer.
The pre-evaluation makes using the evaluateFlag method simpler for the client-side SDK. Instead of having to process each flag based on user context, the SDK simply needs to check the boolean value associated with the flag key since it’s all been pre-evaluated. The developer is also able to provide a default boolean value, similar to the server-side SDK.
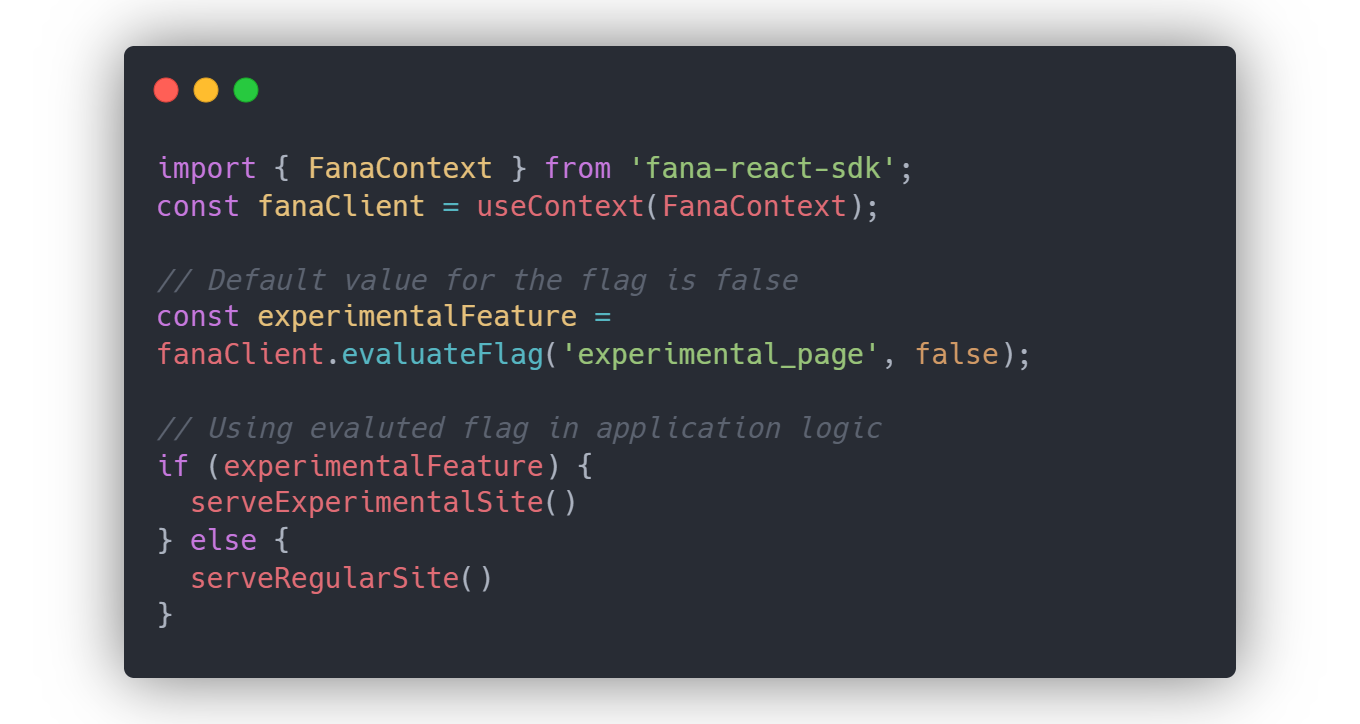
evaluateFlag methodPre-Evaluating Client-Side SDK Data
Flag targeting rules can potentially be set up with sensitive user information, such as names, email addresses, or IP addresses. This can be a concern when working with client-side SDKs, since, if targeting information is being requested on the browser, anyone can see the response.
To mitigate the exposure of sensitive user information, we designed the Flag Bearer to act as a proxy for the data, as described above. This means the only thing that the client browser receives is a list of keys and boolean values, and the potentially sensitive targeting information stays hidden.
6.6.3 SDK Keys
Fána users are provided two separate SDK keys within the Fána dashboard: one for the client-side SDK and one for the server-side SDK. These SDK keys are meant to be provided during the SDK initialization process for the Flag Bearer to validate the request. If the key does not match the Flag Bearer’s key set, the connection request is denied and no data is sent.
Separate SDK Keys
Having separate keys for client and server-side SDKs was an important decision based on security concerns. If Fána only provided one shared SDK key, a savvy malicious end user can get the SDK key from the client-side request (the SDK key is public since it’s a browser request). The user can then use this same SDK key to make a server-side request to fetch the full ruleset, which may contain sensitive data as described in Pre-Evaluating Client-Side SDK Data.
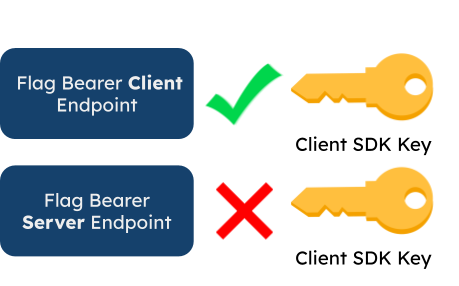
By having two separate SDK keys, the server-side SDK key should never be revealed publicly, thus keeping the sensitive user data safe.
If the server-side SDK key does end up getting compromised, the Fána dashboard offers the option to regenerate either SDK key, invaliding the current one. The regeneration process is not to be taken lightly, as it will block any future initialization attempts until the old SDK key is replaced within the application code.
6.7 Final Architecture
The final architecture of Fána with the four major components shown in detail is below.
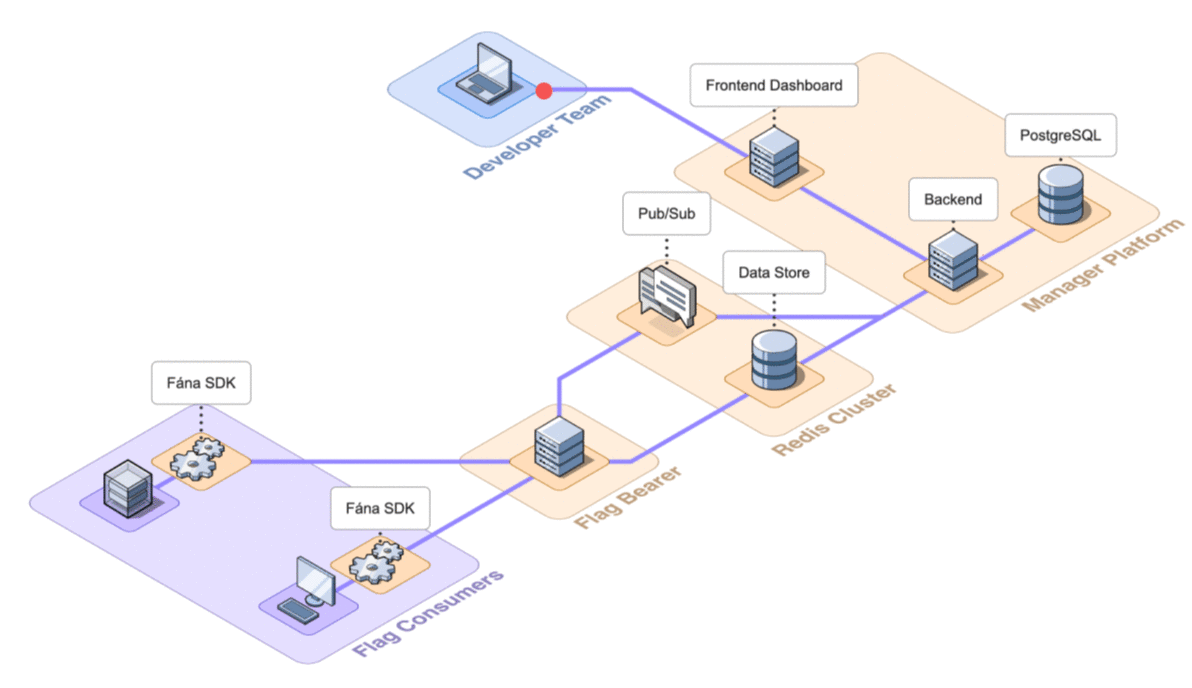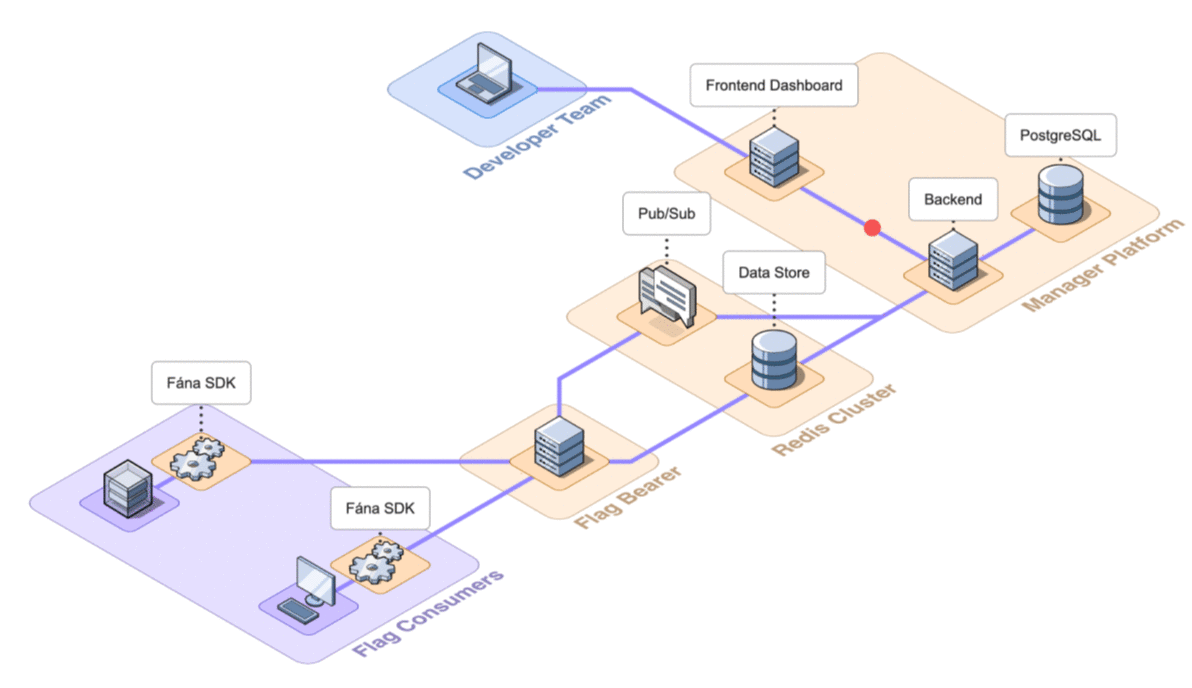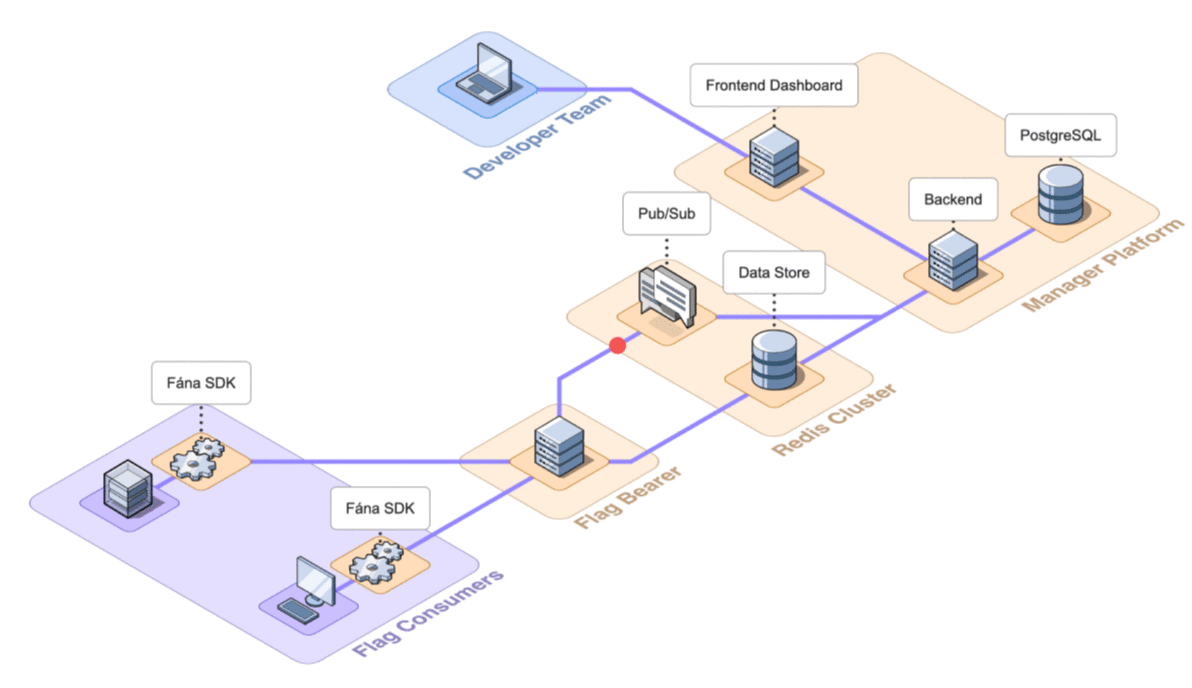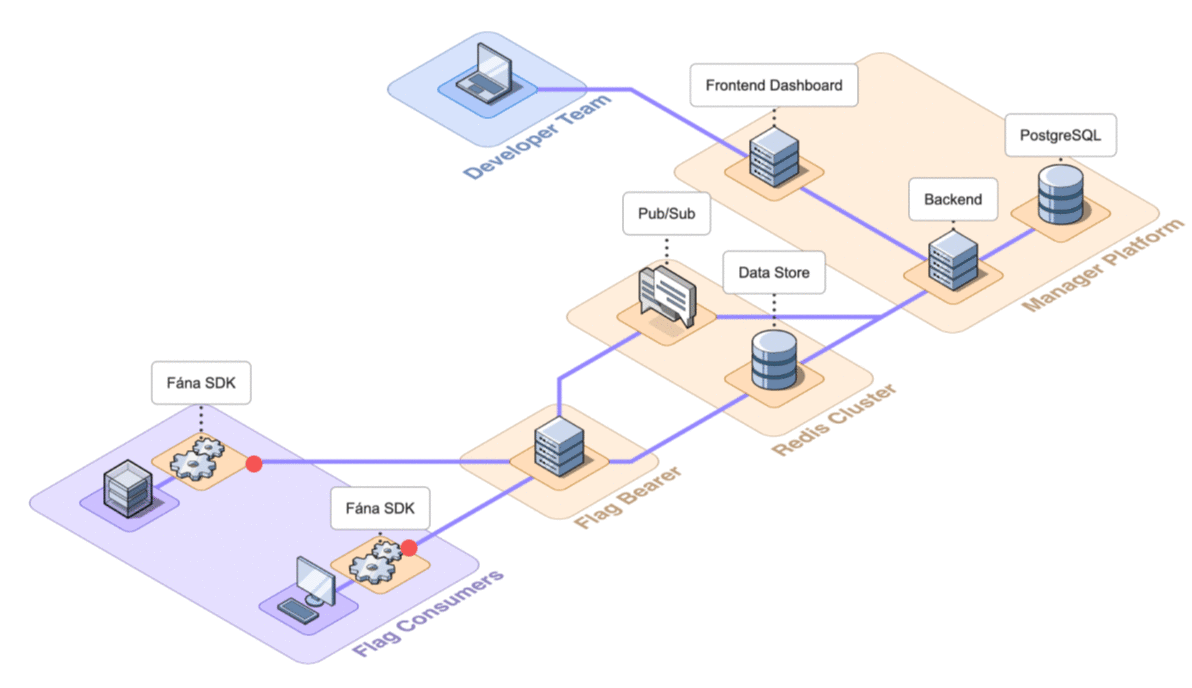
Having established the above architecture and the responsibility of each of the components, the following section will discuss how to deploy the platform for use.
7 Deploying Fána
There are two options for deploying Fána: self-hosted using Docker or cloud-hosted on AWS. Developers interested in using Fana in a self-hosted environment (non-AWS) or are interested in testing out Fana in their local development environment can deploy the entire Fana stack with one command using Docker. Alternatively, developers that are already familiar with the AWS environment can quickly deploy the Fánastack using the provided AWS Cloud Development Kit (CDK) template.
7.1 Docker
Developers who want the flexibility of self-hosting can choose to utilize Fána’s containerized components using Docker. This option allows for Fána to be managed and deployed across any environment of the developer’s choosing.
Developers can also deploy using Fána’s docker-compose.yml file, which will configure and launch the platform in a single Docker network. In this network, the built-in DNS resolution and service definitions in the YAML file will allow the containers to communicate with each other as required.

The docker-compose.yml file references Fána’s latest images for each component as well as utilizing the latest and maintained Redis and PostgreSQL images, which are defined to start up in their dependency order. Developers can configure the necessary administrative variables as well as expose necessary host and port endpoints in the environment file to deploy Fána.
7.2 AWS
Developers who want to leverage AWS’s managed Elastic Container Services (ECS) hosted on AWS Fargate, a serverless, pay-as-you-go compute engine, can choose to utilize Fána’s CDK App to spin up a Fána platform on the cloud.
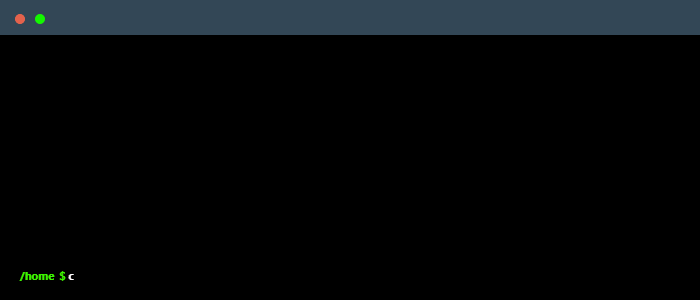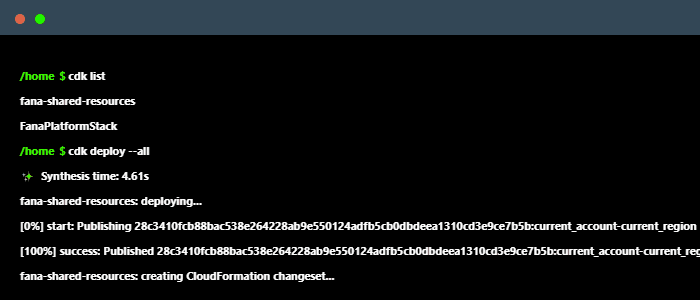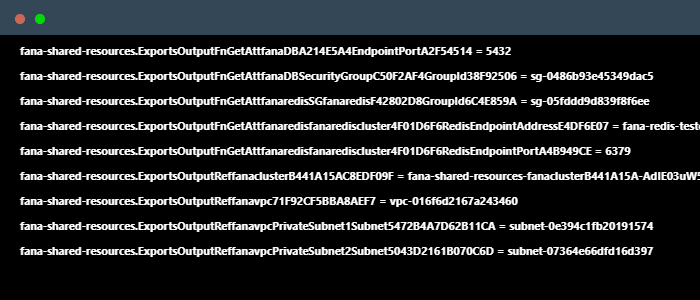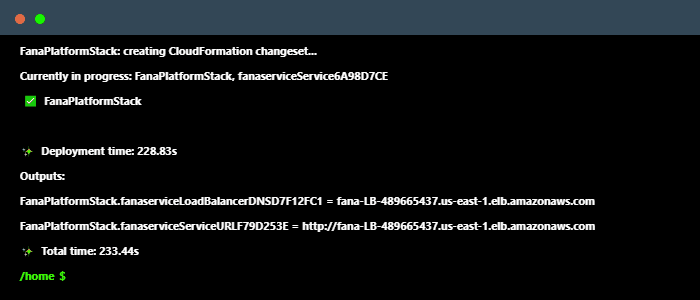
Configuring and deploying each resource on the AWS Console can be error-prone and difficult to replicate. Instead, the cloud infrastructure can be programmatically defined through the CDK framework, which allows developers to specify their infrastructure as code for a much simpler and more convenient deployment process.
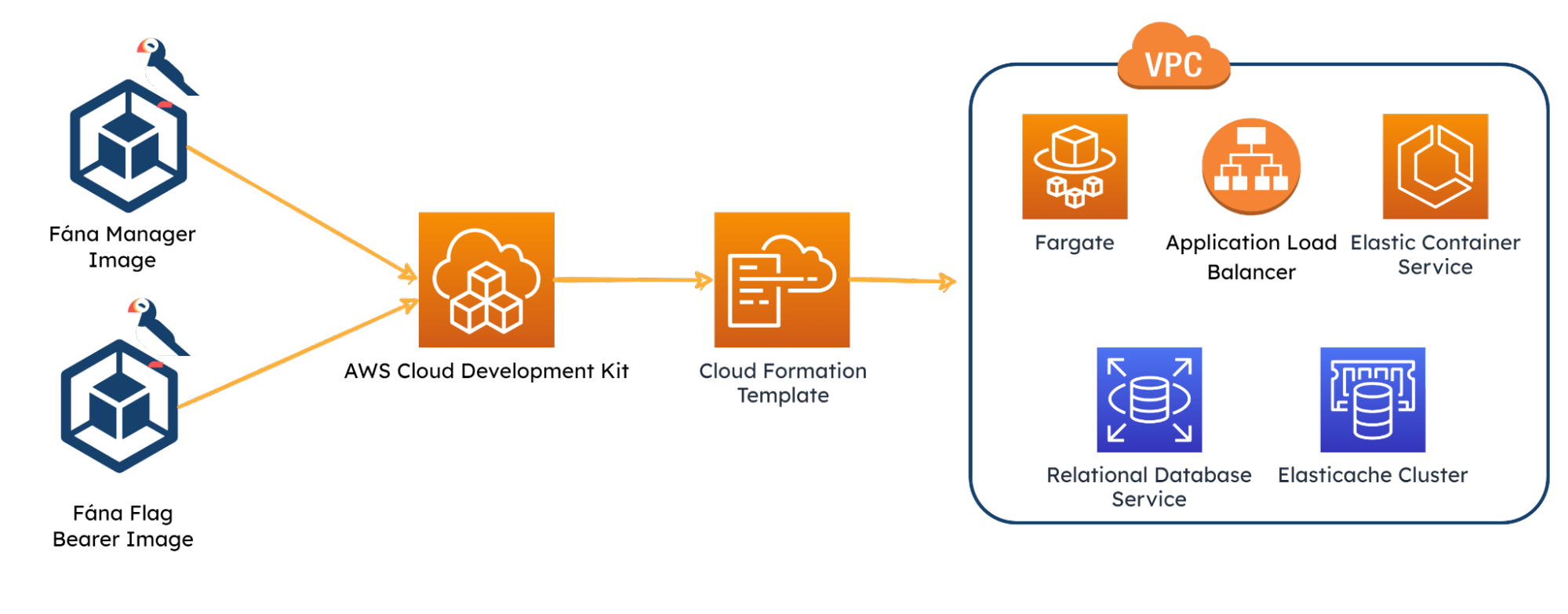
The Fána CDK App defines certain shared resources including a Virtual Private Cloud, which defines a virtual network for the infrastructure to operate in. It also creates a new instance of Relational Database Service (RDS) running on PostgresQL to serve as the persistent database for the platform, as well as an Elasticache Redis cluster to serve as the data store and Pub/Sub.
The shared resources are then referenced in Fána’s overall stack. To allow appropriate traffic through the Fána platform’s network, a new security group is configured and created. A load-balanced Fargate Service that hosts the Fána’s Manager Platform container and Flag Bearer container references the aforementioned security group. Both containers reference AWS’s public Elastic Container Registry to use the latest image versions. Finally, the two containers connect to RDS and/or Elasticache, respectively.
The application load balancer is responsible for routing traffic through the Fána platform. The load balancer is configured with listener rules to target the Manager Dashboard for incoming traffic from developers and to target the Flag Bearer for incoming Client or Server SDK traffic.
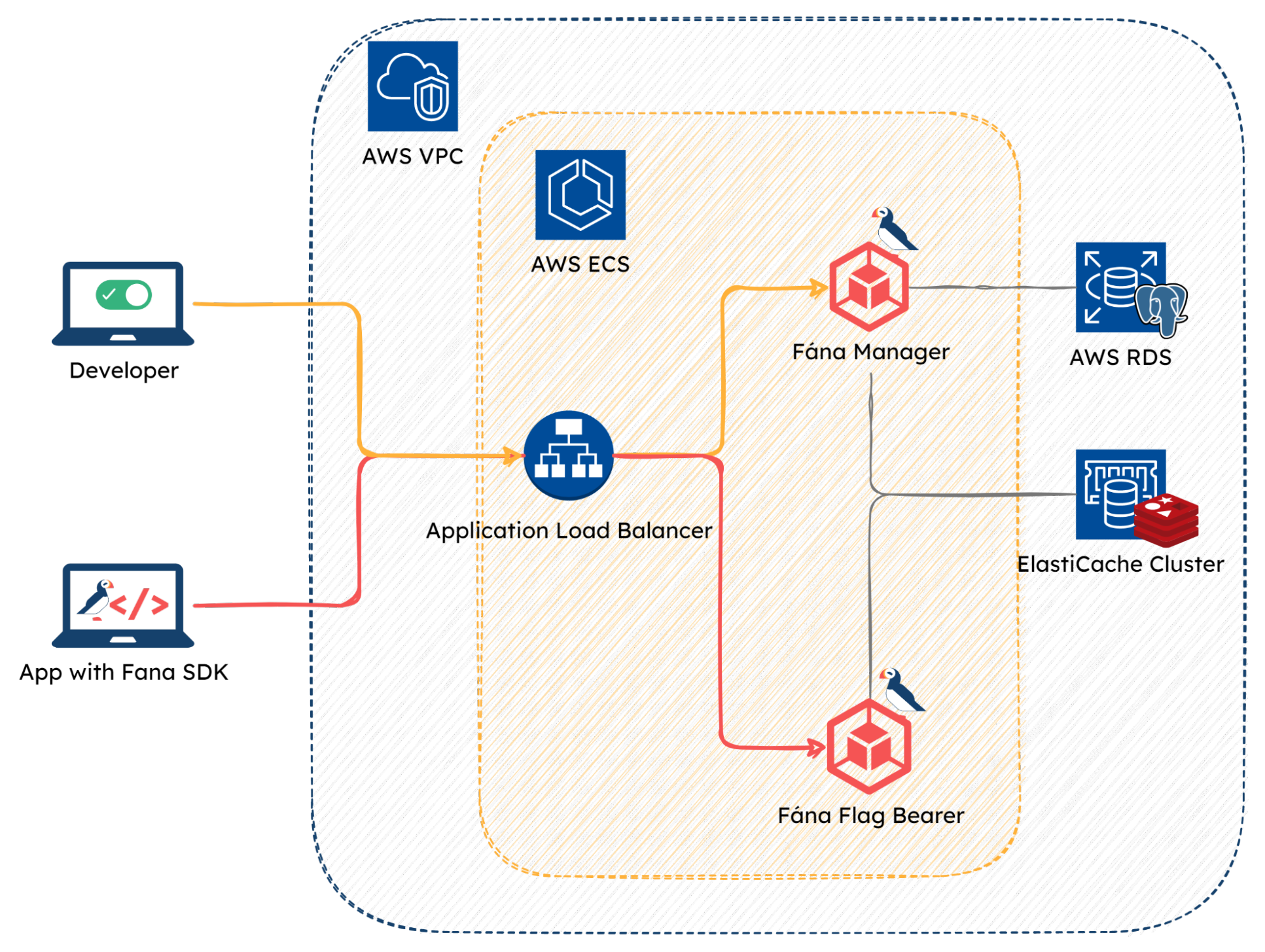
Going back to Fána’s choice of using the Fargate service--as ECS is a container orchestration platform, which manages the life cycle and placement of the tasks or the instances of our docker images, the stack required compute resources to run those containers. The two options the team considered for hosting the containers were: EC2 or Fargate.
With EC2, the developer would need to deploy and manage a cluster of EC2 instances to run the relevant containers. While this allows for greater control over the machines, it increases the developer’s responsibility to provision, scale, and secure the EC2 instances.
The other option was Fargate. With Fargate, developers no longer need to manually provision and manage the compute instances. They can simply create a cluster and specify resources like CPU and memory. When the containers are deployed, Fargate will run and manage the servers to meet those requirements.
As it was important for the Fána platform to be an easily maintainable solution where the engineering team can focus more on the business needs rather than the task of managing the feature flag platform, the Fargate service was a more appropriate choice for hosting and deploying Fána’s stack.
8 Engineering Decisions & Tradeoffs
This section dives deeper into a few of the engineering decisions and tradeoffs the team made throughout Fána’s implementation.
8.1 SQL vs NoSQL
One of the first engineering decisions encountered after prototyping Fána was to evaluate the data model and decide what type of database best fit the data’s characteristics.
8.1.1 MongoDB
The earliest iterations of Fána used MongoDB, a NoSQL document store. Initially, the lack of rigidly-defined schema helped facilitate a quicker setup and iteration for prototyping the minimal viable product (MVP). It was also easier for the Fána team to manipulate the seed data via Atlas, MongoDB’s cloud platform, which assisted with rapid testing.
As the team progressed through the implementation of the platform, the possibility of transitioning over to a relational database model was considered based on the following key characteristics of the data:
- Consistent structure: Flags contain audiences, which contain conditions, which contain attributes.
- Highly relational: Almost all operations executed on the data are cross-entity to serve the dashboard and the Flag Bearer.
- High utilization of joins for CRUD operations: The data model needs to reflect relationships between dynamic entities. For example, updating an audience means that the associated flags are affected.

As the implementation of data model evolved, the flexibility of MongoDB became less of an advantage, and a more intuitive expression of the relationships in the data became more attractive. While the flexibility of a document-model database made MongoDB a viable option, the team decided that the data access patterns, specifically for accessing flag entities and audience entities, lent themselves best to a relational database model.
8.1.2 PostgreSQL
SQL databases, on the other hand, more directly supported the relational nature of the data. Strict schemas support consistent entity models, normalized tables avoid redundancy and duplication, and optimized join queries fulfill the bulk of Fána's database operations. All of these advantages more immediately satisfied the application's data requirements.
With these facts in mind, the team concluded that a relational SQL database fits the data structure well. In the end, the open source option of PostgreSQL was chosen due to its versatility and accessibility.
8.2 Decoupling Manager Responsibilities
The initial MVP design for Fána consisted of just a Flag Manager with a rudimentary dashboard and database, as well as SDKs. This loaded several responsibilities onto the Manager:
- Handling all database CRUD operations
- Serving the dashboard
- Validating SDK initialization requests
- Compiling the entire flag ruleset on each SDK initialization request
- Maintaining SDK SSE connections to provide real-time updates
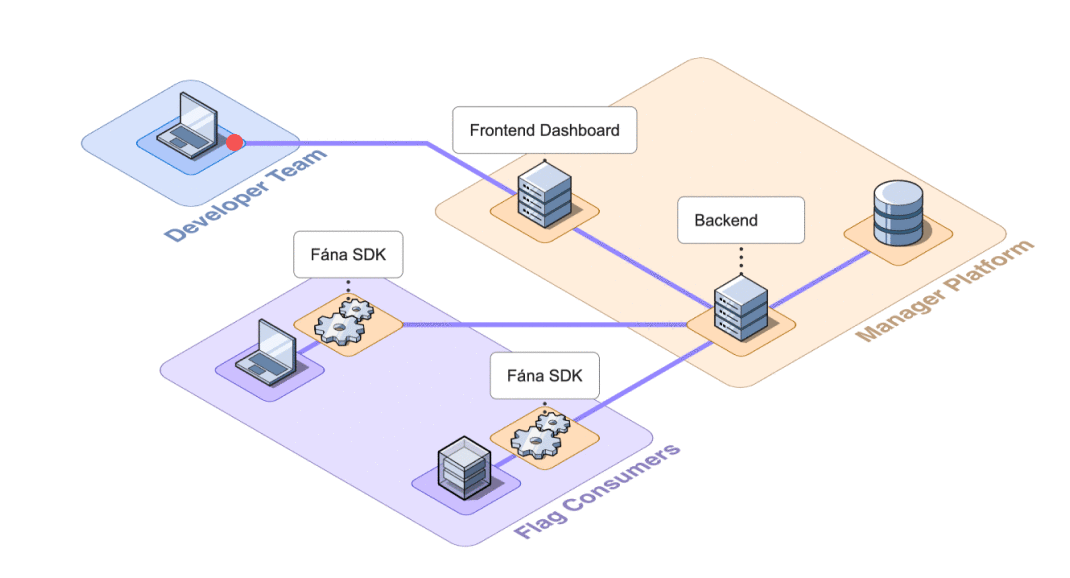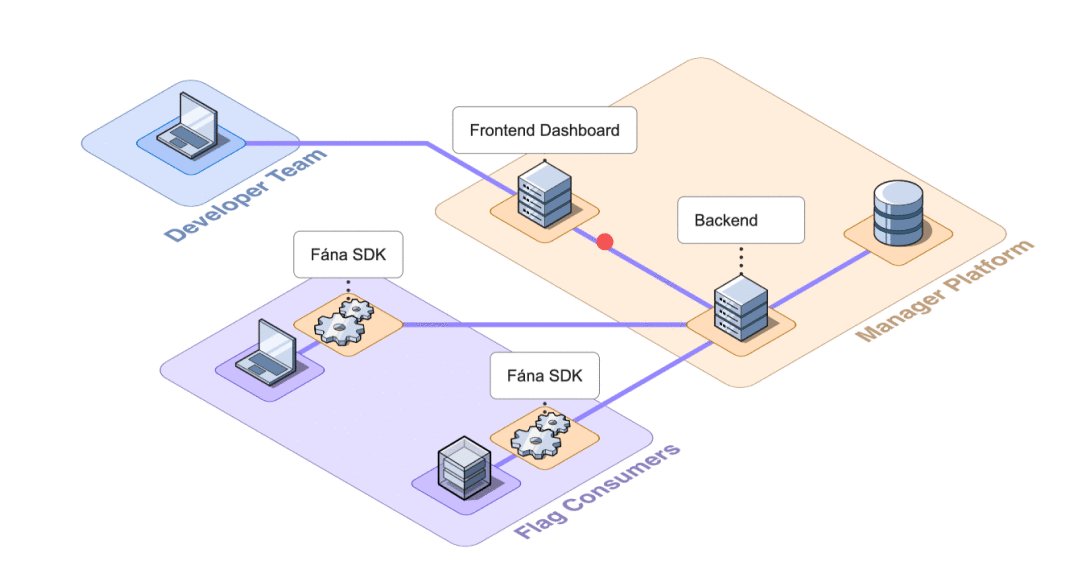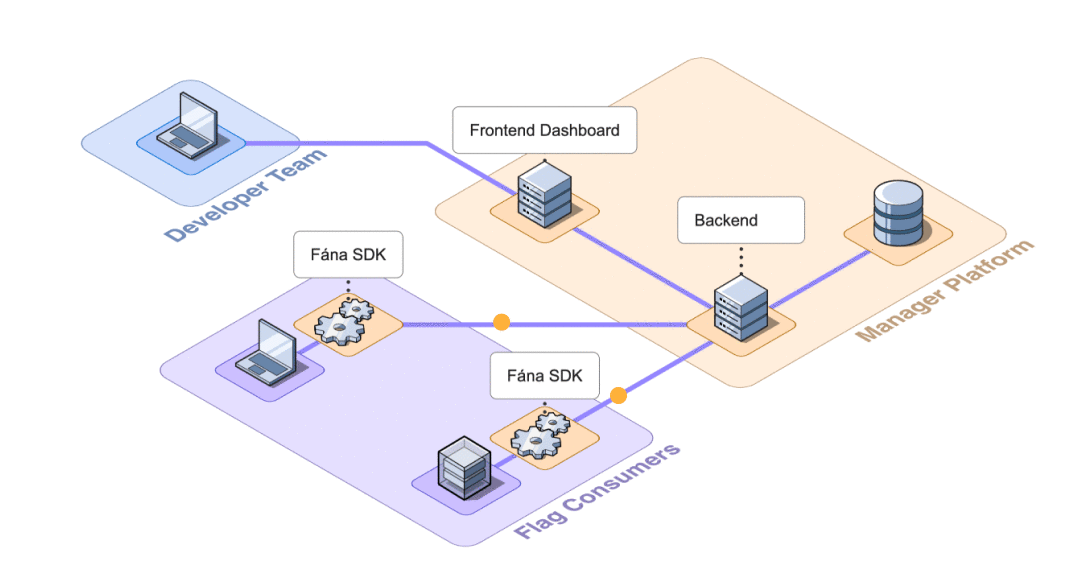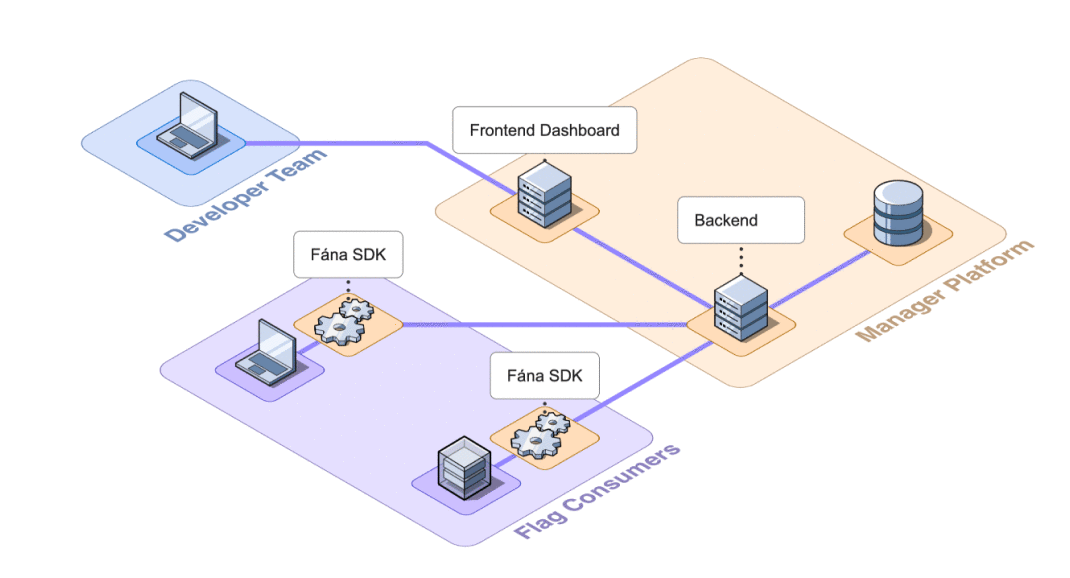
This aggregation of responsibilities presented an opportunity for decoupling. Separating concerns would reduce the overall complexity of the Manager as well as accommodate scaling individual components as needed.
8.2.1 Decoupling SDK Connections
In the initial design, the Manager was responsible for SDK communication, including initializations and SSE streaming. This meant that every SDK that was initialized needed to request flag data from the Manager to spin up properly. The Manager was also responsible for sending out push events to an SSE stream for every connected SDK when an update was made.
As the number of connected SDKs increased, the potential for the Manager to become inundated with requests also increased, which introduced a bottleneck risk. To offload the responsibility of managing SDK communication, the Fána team built the Flag Bearer component
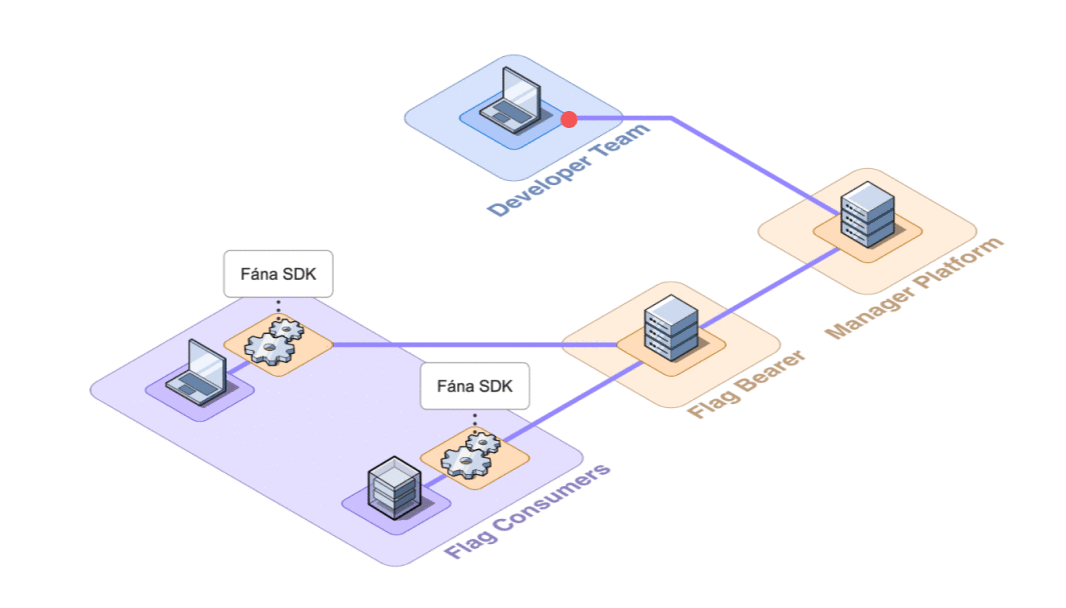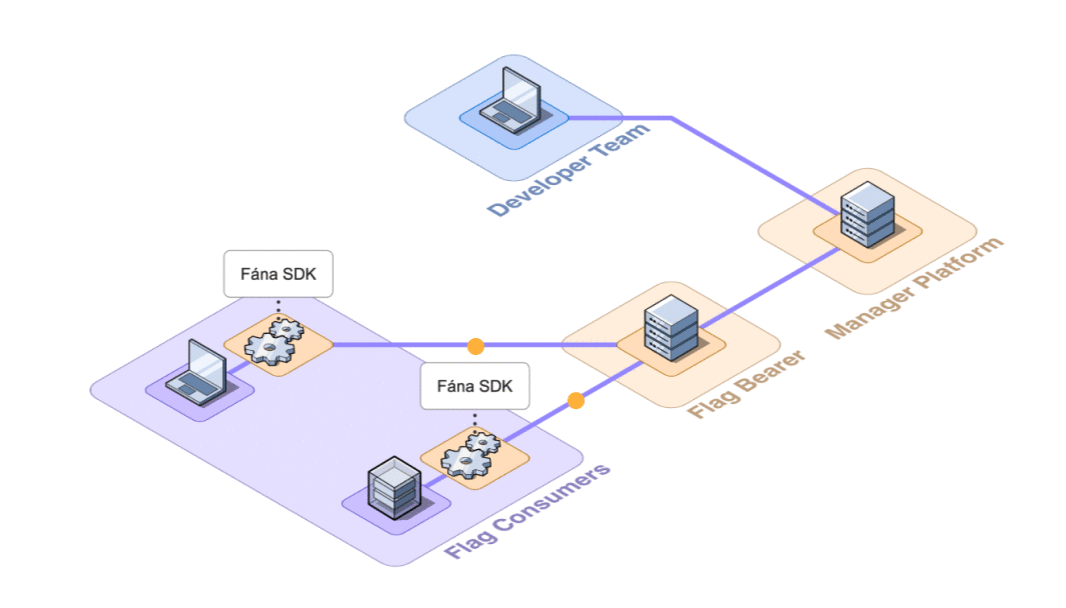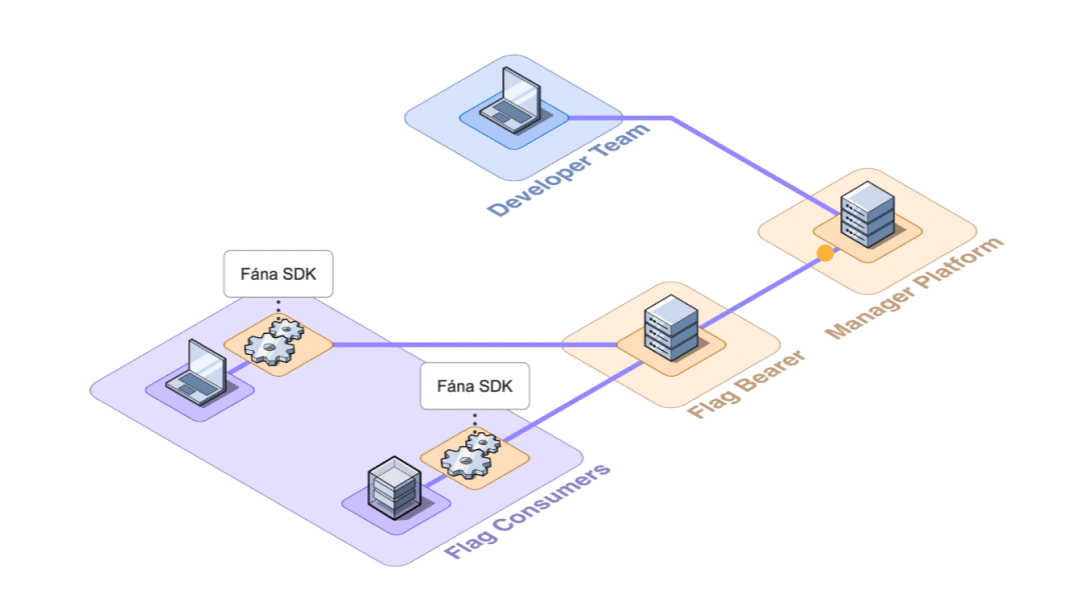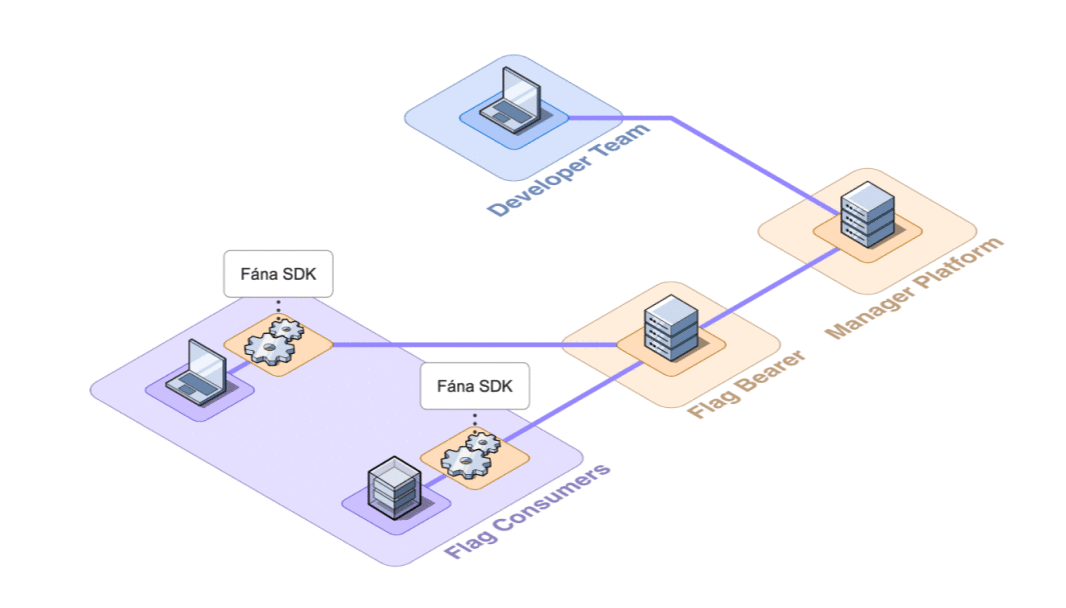
The Flag Bearer acts as an intermediary between the SDK and the Manager. It handles the responsibility of initializing SDKs and maintaining SSE connections. Since it is decoupled from the Manager, it can be scaled on its own, as needed.
While adding another component to our architecture adds structural complexity, being able to ease the burden on the Manager was worth the tradeoff, especially since it makes scaling more feasible.
This relieved the Manager of directly communicating with SDKs, but this setup still required the Flag Bearer to reach out to the Manager to access the latest flag ruleset data whenever an SDK connected to the Flag Bearer. This challenge led to the next step in the architecture evolution of decoupling data provisioning.
8.2.2 Decoupling Data Provisioning
The PostgreSQL database is Fána’s source of truth and is controlled by the Manager. However, the Flag Bearer needs to read this data fairly often to initialize SDKs.
As new flags and audiences are created, the size of the overall ruleset payload increases. Since the payload needs to be sent every time an SDK initializes, this creates more work for the Manager as it needs to compile the data into the overall ruleset from the database on every request. Larger data payloads also naturally take longer to reach their destination.
The Fána team considered having the Flag Bearer hold its own copy of the flag ruleset data in-memory. However, it was ultimately decided to decouple this responsibility further to preserve the Flag Bearer’s ability to independently scale by storing the flag data in a data store.

Instead of having the Flag Bearer manage its own flag ruleset or reach out to the Manager every time it needed the data, a Redis data store layer was implemented to reduce read requests to the database. Every time a write operation is made to the database from the developer dashboard, the Manager refreshes the data store with the latest compiled flag ruleset.
The Flag Bearer is now able to ping the data store instead of the Manager, easing the load. The Manager’s responsibilities have been pared down to managing flag data and serving the dashboard. The Manager only needs to compile the flag ruleset data whenever a change is made, rather than every time an SDK is initialized.
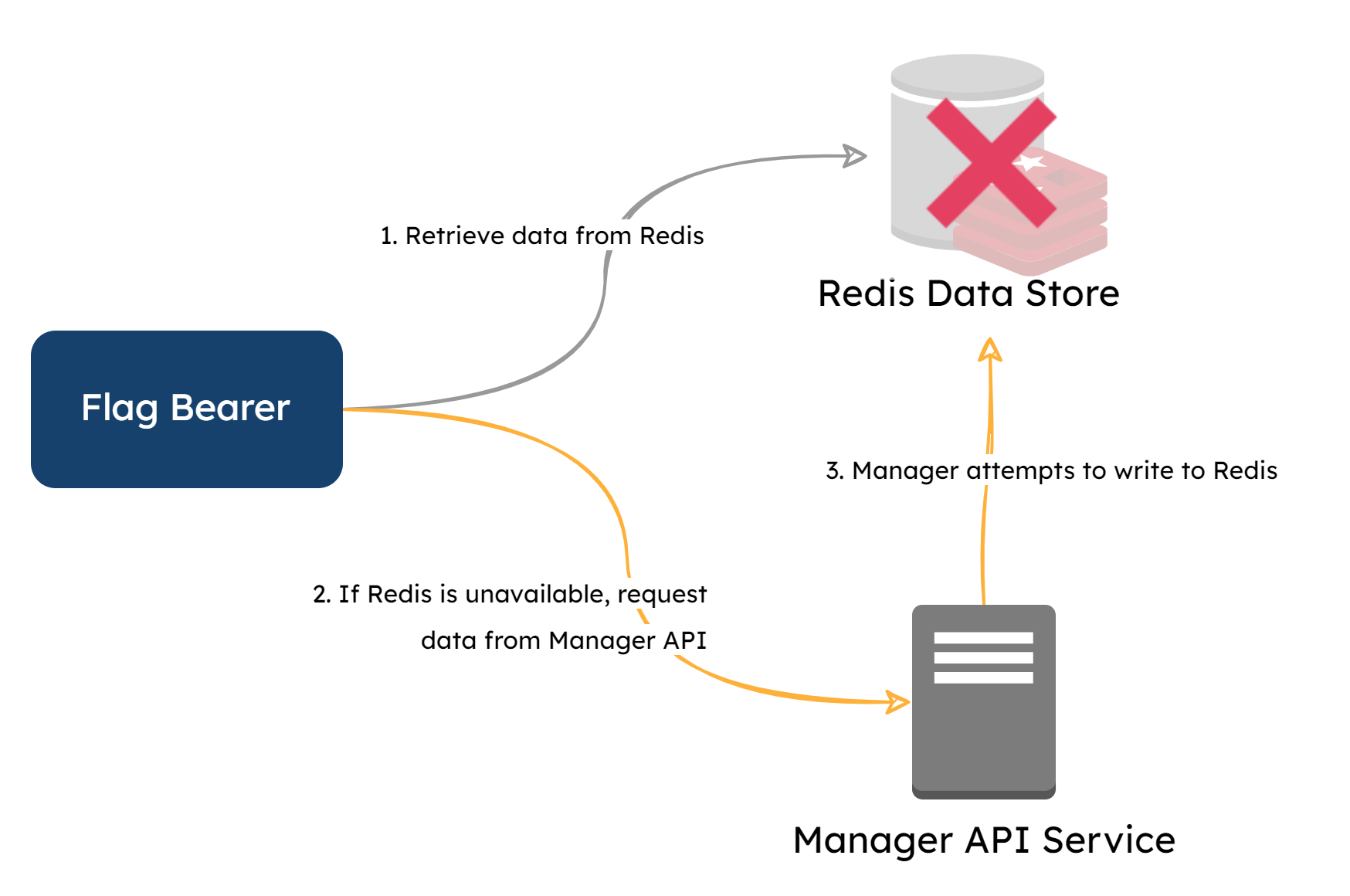
A degree of fault tolerance was also built into the Redis data store workflow. If the data store is unavailable, the Flag Bearer will reach out to the Manager for a copy of the data. When a request comes from the Bearer, it implies a fault with the data store, and the Manager will attempt to repopulate it. This fault tolerance adds a layer of assurance that SDKs can still receive the necessary flag data on initializations, even if the data store is unavailable or unreachable.
8.3 Communicating Between Components
One of the primary requirements driving the inter-component communication decisions was enabling real-time evaluation of the flag data. The reason real-time updates are critical to Fána goes back to the core dynamic for choosing a feature flag platform for testing in production in the first place. Specifically, if something goes wrong with a feature deployment, that issue’s impact on users is a function of the response time to addressing that issue. In other words, rolling back bad code as soon as possible is essential.
The data’s distribution journey can be broken down into two parts: the first step was getting the flag rules from the database to the Flag Bearer nodes, and the second step was getting those flag rules out to the SDKs.
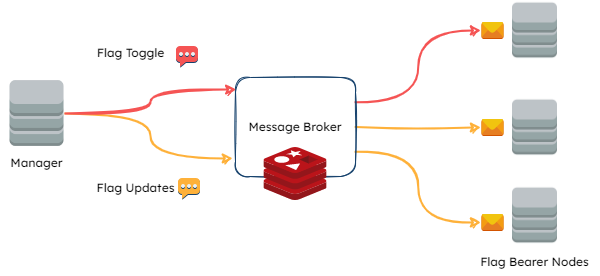
8.3.1 Manager to Flag Bearer Communication
The Manager needs some way to communicate updates to the Flag Bearer in real-time. Three options that were explored for this were API requests, Webhooks, and Publisher/Subscriber messaging.
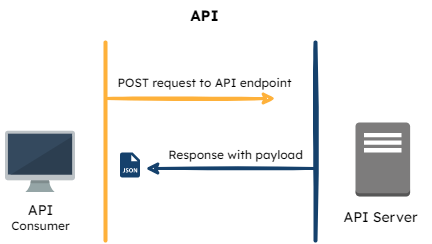
API Requests
One approach to serving the Flag Bearer would be to establish the Manager as an API server to respond to requests from the Flag Bearer. This is a well-established pattern but it came with some tradeoffs:
- Manager would still be required to serve every request for flag rule data, which compounds its responsibilities and increases queries to the database.
- The Flag Bearer does not have a way of knowing when updates are made to the flag rule set. This means that the Flag Bearer needs to make requests to the Manager to ensure that the most current rule set is being served whenever a new SDK request comes in. Additionally, Flag Bearer would not have access to any rule set updates in real time.
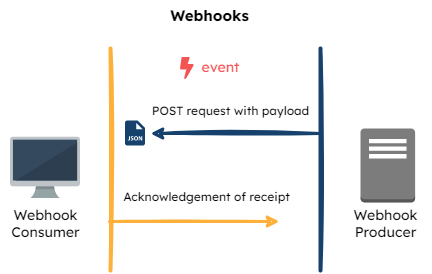
Webhooks
The first iterations of Fána utilized webhooks for event-driven communication between the Manager and Flag Bearer. With webhooks, Flag Bearer was able to maintain a copy of the most current rule set in-memory, eliminating the need to make requests to the Manager at every SDK request. However, in order to accommodate different types of events (i.e., flag and audience updates versus simple flag toggle updates), the design would need to consider the following:
- Creating multiple URI endpoints to distinguish flag rule updates from flag toggle updates; or
- Providing the entire flag data within the payload for each updates, which would impose an additional computational load on the Flag Bearer to parse and determine what update has been made to the flag rule set.
While webhooks allow the Flag Bearer to receive real-time updates and reduce traffic to the Manager, it still adds complexity to the Flag Bearer to handle ingesting and distributing of event notifications.
Publisher/Subscriber Model
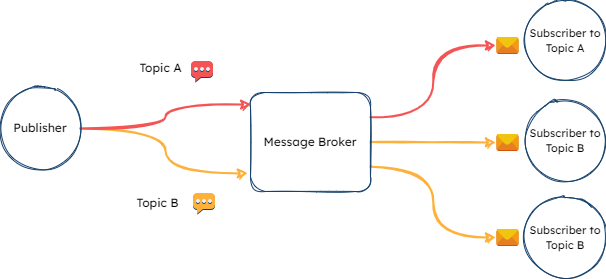
The pub/sub model is another event-driven approach that decouples the message sender from the message consumer by introducing a separate component between them. In Fána’s case, the Manager was the publisher and the Flag Bearer was the subscriber. Placing the pub/sub in between the Manager and the Flag Bearer met two main criteria:
- Achieving real-time, event-driven communication for flag updates.
- Handling different types of updates through the use of message topics or channels
Additionally, this architecture minimized the communication responsibilities and dependencies of the Manager and the Flag Bearer components, allowing greater flexibility and ability to independently scale as needed.
Once the Flag Bearer subscribes to receive real-time event notifications, it would need a way to communicate them to the SDKs. The following sections will discuss the different options considered to facilitate this final leg of the communication.
8.3.2 Flag Bearer to SDK Communication
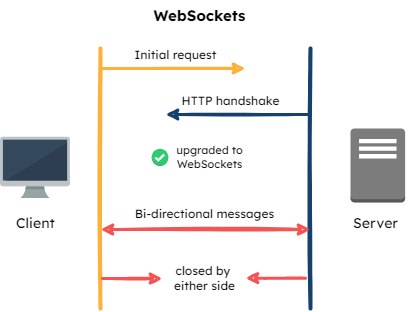
Three options were considered for the SDKs to be able to retrieve the latest set of flag data from the Flag Bearer: polling, WebSockets, and SSE.
Polling
With polling, the SDK makes requests for updated data from the Flag Bearer at a specified interval. For example, setting the polling interval to 30 seconds, all connected SDKs will ping the Flag Bearer every 30 seconds, and the Bearer would provide each of them with the newest ruleset.
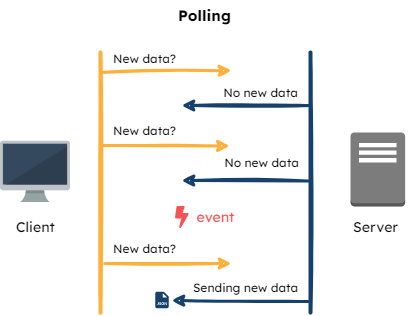
Since updates are only reflected at the interval points, this is not truly a real-time solution. The majority of the polling requests may end up being unnecessary since they could just be fetching the same set of data for extended periods. It may also be a significant load on the Bearer, considering that the number of connected SDKs can be quite high, depending on the number of applications utilizing Fana’s SDKs.
WebSockets
A WebSocket is a full-duplex (bi-directional) communication channel between a client application and a server. After the client’s connection request is accepted by the server, they can now freely communicate.
While this does allow for real-time updates, the bi-directional communication is not necessary--only the Flag Bearer needs to relay information to the SDKs. Additionally, WebSockets does not automatically attempt to reconnect if the connection is dropped.
SSE
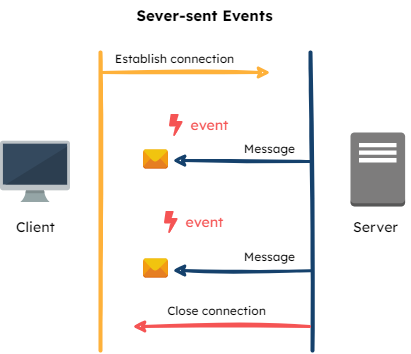
Last, SSEs are similar to WebSockets in that they open a persistent connection between a client application and server, except SSEs are uni-directional. They also have built-in support for re-establishing dropped connections every 60 seconds. The combination of these traits made SSEs the most appropriate real-time communication mechanism for sending flag updates from the Flag Bearer to the SDKs.
9 Summary & Future Work
In summary, Fána provides a lightweight, easy-to-manage feature flagging platform that enables developers to test their features in production by creating flexible and reusable audiences to target their feature release to. This gives developers the control and confidence to gradually release a feature to more and more users over time.
The team recognizes that there is potential for improvement in Fána’s functionality. The following are some additional improvements to consider in the future that could add value to developers utilizing Fána.
9.1 Edge Computing
In a future iteration of Fána’s cloud architecture, the SDK initialization times could be optimized by leveraging edge computing via a network of servers provided by content delivery networks (CDNs). Instead of connecting to the Flag Bearer, SDKs can connect to the nearest CDN node to retrieve flag evaluations. A serverless function that runs at the edge, such as an AWS Lambda@Edge or Cloudflare Worker, could execute the flag evaluation logic much closer to the SDK, reducing overall latency. This node could also access flag data closer to the edge, such as from AWS CloudFront or a Cloudflare K/V. The result is a lower-latency round-trip for initializations, which could boost loading speeds for applications utilizing Fána.
When implementing this strategy, LaunchDarkly saw a 10x improvement in connection speed performance when leveraging their CDN, from 250ms per initialization down to 25ms.[8]
9.2 Supporting Multiple Environments
Some feature flag service providers offer the ability to create multiple environments (such as development, staging, and production) for each flag. This can be useful in situations where a developer wants to test changes to the flag’s targeting logic in an environment without affecting the flag status that is live in the production environment.
While Fána’s current design does not support SDK key creation for specific environments, users can still leverage Fána’s flexibility to duplicate a flag and limit the audience to test groups. While this can be worked around via creating test flags or even rolling out another instance of the architecture, multiple environments could add more convenience for the developers.
9.3 Collecting Metrics
Some feature flag platforms offer flag-related metric collection to support more robust management of feature flags. For example, a developer could see how many times a flag was evaluated in the code as well as the count of true or false results. The developer may also be able to see the date the flag was last evaluated.
This kind of data in a flag management platform would make it easier for developers to manage technical debt by more easily identifying feature flags that are no longer in use or do not need to remain in the codebase. By leveraging these metrics, developers could create workflows to periodically remove flags from features that transition from experimental or temporary to permanent after a feature has been successfully released to the general audience for a certain amount of time. To accommodate metric collection in the future, a data pipeline from the SDKs to the Manager can be set up to centralize and analyze this data.
References
[1] Ejsmont, A. (2015). In Web scalability for Startup Engineers: Tips & Techniques for Scaling Your Web Application (p. 333). book, McGraw-Hill Education.
[2] Clemson, T. (2022, November 18). Testing strategies in a microservice architecture. martinfowler.com. Retrieved August 21, 2022, from https://martinfowler.com/articles/microservice-testing/
[3] Stokes, S. (2016, July 11). Move fast with confidence. Coding with Honour. Retrieved August 21, 2022, from https://blog.samstokes.co.uk/blog/2016/07/11/move-fast-with-confidence/
[4] Stokel-Walker, C. (2019, August 23). What broke the bank. Increment. Retrieved August 21, 2022, from https://increment.com/testing/what-broke-the-bank/
[5] Wong, K. (2020, June 1). Using feature flags to enable nearly continuous deployment for mobile apps. Medium. Retrieved August 21, 2022, from https://medium.com/vmware-end-user-computing/using-feature-flags-to-enable-nearly-continuous-deployment-for-mobile-apps-b6d0940657ff
[6] LaunchDarkly. (2022, August 19). Atlassian case study. LaunchDarkly. Retrieved August 21, 2022, from https://launchdarkly.com/case-studies/atlassian/
[7] Featurehub. (n.d.). Featurehub architecture - FeatureHub Docs. Retrieved August 21, 2022, from https://docs.featurehub.io/featurehub/latest/architecture.html#_nats
[8] LaunchDarkly. (2022, August 19). Evolving Global Flag Delivery - flag delivery at edge. LaunchDarkly. Retrieved August 21, 2022, from https://launchdarkly.com/blog/flag-delivery-at-edge/
Presentation
Team



